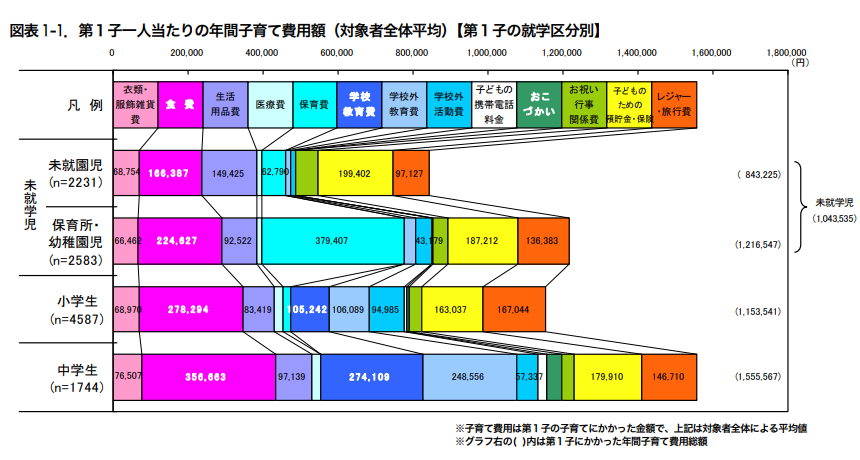
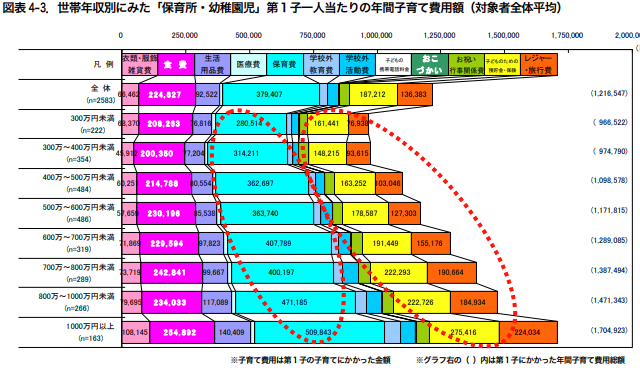
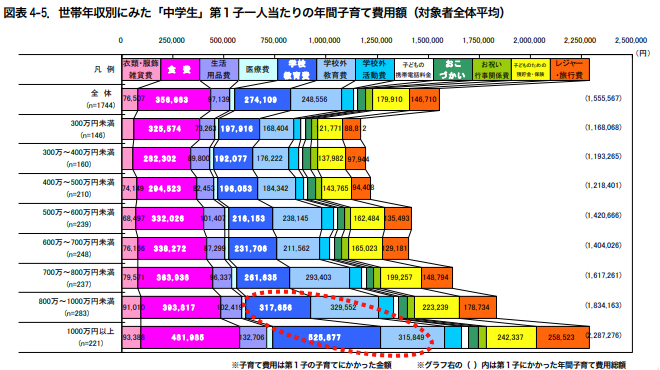
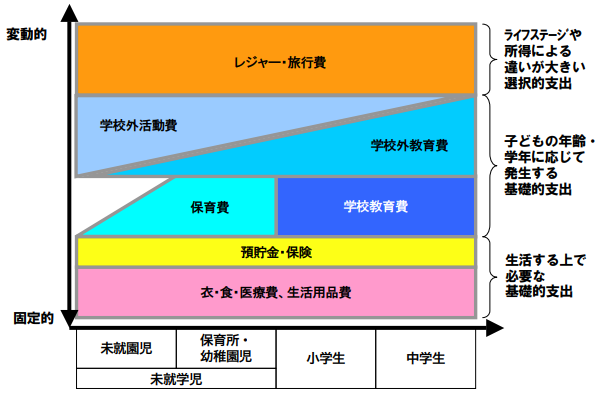
自宅にあるオンプレマシンでグラフィックカードを GPGPU の用途に使用していると、消費電力や発熱は切実な問題になりうる。 特に昨今は電気代の値上がりも著しいし、発熱は製品寿命の短縮や夏だと室温の上昇につながる。 そこで、今回は Linux の環境で nvidia-smi(1) を使って NVIDIA の GPU にパワーリミットを設定することで消費電力や発熱の低減を目指してみる。
使った環境は次のとおり。 Ubuntu 20.04 LTS のマシンに、Docker と nvidia-container-toolkit がインストールしてある。
$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.4 LTS Release: 20.04 Codename: focal $ uname -srm Linux 5.13.0-51-generic x86_64 $ docker version Client: Docker Engine - Community Version: 20.10.17 API version: 1.41 Go version: go1.17.11 Git commit: 100c701 Built: Mon Jun 6 23:02:57 2022 OS/Arch: linux/amd64 Context: default Experimental: true Server: Docker Engine - Community Engine: Version: 20.10.17 API version: 1.41 (minimum version 1.12) Go version: go1.17.11 Git commit: a89b842 Built: Mon Jun 6 23:01:03 2022 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.6.6 GitCommit: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 runc: Version: 1.1.2 GitCommit: v1.1.2-0-ga916309 docker-init: Version: 0.19.0 GitCommit: de40ad0 $ nvidia-smi Fri Jun 24 18:59:39 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.48.07 Driver Version: 515.48.07 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A | | 0% 40C P8 7W / 170W | 14MiB / 12288MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 1087 G /usr/lib/xorg/Xorg 9MiB | | 0 N/A N/A 1232 G /usr/bin/gnome-shell 3MiB | +-----------------------------------------------------------------------------+
もくじ
事前準備
ベンチマーク用に PyTorch を使いたいので、あらかじめ公式の Docker イメージをプルしておく。 そして、コンテナから GPU が見えることを確認する。
$ docker pull pytorch/pytorch $ docker run --gpus all --rm -it pytorch/pytorch nvidia-smi Fri Jun 24 19:03:09 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.48.07 Driver Version: 515.48.07 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A | | 0% 39C P8 8W / 170W | 14MiB / 12288MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| +-----------------------------------------------------------------------------+
GPU で使用できるパワーリミットを確認する
まずは使っている GPU に設定できる最低・最大のパワーリミットを確認する。 今回使った製品であれば、最低が 100W で最大が 170W だと分かる。 デフォルトではパワーリミットの値は最大に設定されているはず。
$ nvidia-smi -q -d POWER ==============NVSMI LOG============== Timestamp : Fri Jun 24 19:05:09 2022 Driver Version : 515.48.07 CUDA Version : 11.7 Attached GPUs : 1 GPU 00000000:01:00.0 Power Readings Power Management : Supported Power Draw : 7.75 W Power Limit : 170.00 W Default Power Limit : 170.00 W Enforced Power Limit : 170.00 W Min Power Limit : 100.00 W Max Power Limit : 170.00 W Power Samples Duration : 105.50 sec Number of Samples : 119 Max : 8.42 W Min : 7.46 W Avg : 7.79 W
GPU にパワーリミットを設定する
GPU にパワーリミットを設定するには nvidia-smi(1) の -pl オプションを使う。
このオプションに、先ほど得られた設定できるパワーリミットの範囲でワット数を指定すれば良い。
たとえば、今回の環境における下限の 100W に設定するには次のようにする。
$ sudo nvidia-smi -pl 100 Power limit for GPU 00000000:01:00.0 was set to 100.00 W from 170.00 W. All done.
もう一度 nvidia-smi(1) をオプションなしで実行してみると、ワット数の表示が 100W になっていることが確認できる。
$ nvidia-smi Fri Jun 24 19:06:28 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.48.07 Driver Version: 515.48.07 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A | | 0% 39C P8 9W / 100W | 14MiB / 12288MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 1087 G /usr/lib/xorg/Xorg 9MiB | | 0 N/A N/A 1232 G /usr/bin/gnome-shell 3MiB | +-----------------------------------------------------------------------------+
パワーリミットを設定してベンチマークを測ってみる
さて、パワーリミットを設定すれば、各瞬間の電力 (W) が減るのは分かる。 一方で、時間を通じた総和として消費電力量 (Wh) が減るのかは分からない。 そこで、パワーリミットを最小と最大に設定した状態でのパフォーマンスを調べる。
PyTorch のコンテナを起動する。
$ docker run --gpus all --rm -it pytorch/pytorch
動かすベンチマークについては、下記の PyTorch の公式チュートリアルを参照にした。
下記のサンプルコードでは、内積を計算するシンプルなコードを使ってベンチマークする。
$ cat << 'EOF' > benchmark.py import torch import torch.utils.benchmark as benchmark def batched_dot_bmm(a, b): '''Computes batched dot by reducing to bmm''' a = a.reshape(-1, 1, a.shape[-1]) b = b.reshape(-1, b.shape[-1], 1) return torch.bmm(a, b).flatten(-3) # Input for benchmarking x = torch.randn(100000, 10000, device='cuda') t = benchmark.Timer( stmt='batched_dot_bmm(x, x)', setup='from __main__ import batched_dot_bmm', globals={'x': x}, ) print(t.timeit(1000)) EOF
まずはパワーリミットを下限の 100W に設定した状態で実行する。 同時に、nvidia-smi(1) を実行して、消費電力が上限の 100W に張り付くことを確認しておこう。
# python benchmark.py <torch.utils.benchmark.utils.common.Measurement object at 0x7fd2ba7fa460> batched_dot_bmm(x, x) setup: from __main__ import batched_dot_bmm 16.23 ms 1 measurement, 1000 runs , 1 thread
上記から、1 回の演算に平均で 16.23ms かかることがわかった。
続いてはパワーリミットを上限の 170W に戻す。
$ sudo nvidia-smi -pl 170 Power limit for GPU 00000000:01:00.0 was set to 170.00 W from 100.00 W. All done.
そして、プログラムをもう一度実行する。 今度も、nvidia-smi(1) を実行して、消費電力が上限の 170W に張り付くことを確認しておこう。
# python benchmark.py <torch.utils.benchmark.utils.common.Measurement object at 0x7ff3be37b460> batched_dot_bmm(x, x) setup: from __main__ import batched_dot_bmm 13.76 ms 1 measurement, 1000 runs , 1 thread
上記から、今度は 1 回の演算に平均で 13.76ms かかることがわかった。
演算にかかる電力は 170W と 100W なので約 40 % 低下している。
そして、演算にかかる時間は 13.76ms と 16.23ms なので約 18 % 増加した。
ここから、トータルの電力量は 100W において 0.6 * 1.18 = 0.708 になる。
あくまで今回の条件下ではという但し書きはつくものの、計算に使用する電力量は約 71% まで減らせたようだ。
一般に半導体のワットパフォーマンスはリニアな関係ではなく、入力する電力が大きくなるほどパフォーマンス向上の効率が悪くなると言われる。 その点からも、今回の結果には納得がいく。 また、電力量が減れば発熱も小さくなるため、暖房器具としての性能も低下するし製品寿命の延長が望める可能性もある。
まとめ
今回は nvidia-smi(1) を使って NVIDIA の GPU にパワーリミットを設定して消費電力と発熱の低減を試みた。 オンプレマシンの消費電力や発熱に悩んでいる場合には、パフォーマンスとのトレードオフはあるものの、一考の余地はあるかもしれない。
いじょう。