WLX212 に関しても、コンソールポートからコマンドラインで設定できる。
とはいえ、機能的には無線 LAN アクセスポイントに過ぎないので Web UI からの設定でも十分に事足りる。
YAMAHA のルータと併用している場合には、ルータの Web UI からリバースプロキシの機能で管理画面にアクセスできる。
また、LANマップ機能を使うと接続している機器が一元的に確認できるので便利だった。
午後問題も、基本的には過去問を解いて対策した。
なお、データベーススペシャリスト試験の午後問題には、午後 I と午後 II の両方で必ず出題されるジャンルがある。
それが「概念データモデルと関係スキーマ」という問題で、受験者からは「お絵かき問題」という通称で呼ばれることがある。
お絵かき問題と呼ばれる所以は、未完成の状態で与えられる概念データモデルの図に線を書き入れて完成させるため。
そして、過去問を解いていくと、どうやら自分が「お絵かき問題」を苦手としていることが分かってきた。
より具体的には、正解を導くことはできても時間がかかってしまう。
この点は、特に午後 I において問題となった。
なぜなら、午後 I はとにかく時間との戦いになるため。
午後 I は 90 分で大問 3 問から 2 問を選んで解くため、1 問あたり 45 分しか使えない。
分からない部分があっても、時間配分を決めてある程度は見切りをつけていかないと、最終的に全く時間が足りなくなる。
>>> from sklearn.datasets import fetch_openml
>>> df_pandas, _ = fetch_openml(
... "diamonds",
... version=1,
... as_frame=True,
... return_X_y=True,
... parser="pandas"
... )
>>> df_pandas.head()
carat cut color clarity depth table x y z
00.23 Ideal E SI2 61.555.03.953.982.4310.21 Premium E SI1 59.861.03.893.842.3120.23 Good E VS1 56.965.04.054.072.3130.29 Premium I VS2 62.458.04.204.232.6340.31 Good J SI2 63.358.04.344.352.75
$ sudo ip link add client-veth0 type veth peer name proxy-veth0
$ sudo ip link add server-veth0 type veth peer name proxy-veth1
作成したインターフェイスを Network Namespace に所属させる。
$ sudo ip link set client-veth0 netns client
$ sudo ip link set proxy-veth0 netns proxy
$ sudo ip link set proxy-veth1 netns proxy
$ sudo ip link set server-veth0 netns server
インターフェイスが利用できるように状態を UP に設定する。
$ sudo ip netns exec client ip link set client-veth0 up
$ sudo ip netns exec proxy ip link set proxy-veth0 up
$ sudo ip netns exec proxy ip link set proxy-veth1 up
$ sudo ip netns exec server ip link set server-veth0 up
また、Web サーバに対応する Network Namespace の server についてはループバックインターフェースの状態も UP に設定する。
$ sudo ip netns exec server ip link set lo up
最後に、各インターフェイスに IP アドレスを付与する。
$ sudo ip netns exec client ip address add 192.0.2.1/24 dev client-veth0
$ sudo ip netns exec proxy ip address add 192.0.2.254/24 dev proxy-veth0
$ sudo ip netns exec proxy ip address add 198.51.100.254/24 dev proxy-veth1
$ sudo ip netns exec server ip address add 198.51.100.1/24 dev server-veth0
$ sudo ip netns exec router1 sysctl net.ipv4.ip_forward=1
$ sudo ip netns exec router1 sysctl net.ipv4.conf.default.send_redirects=0
$ sudo ip netns exec router1 sysctl net.ipv4.conf.default.accept_redirects=0
$ sudo ip netns exec router1 sysctl net.ipv4.conf.default.rp_filter=0
$ sudo ip netns exec router2 sysctl net.ipv4.ip_forward=1
$ sudo ip netns exec router2 sysctl net.ipv4.conf.default.send_redirects=0
$ sudo ip netns exec router2 sysctl net.ipv4.conf.default.accept_redirects=0
$ sudo ip netns exec router2 sysctl net.ipv4.conf.default.rp_filter=0
それぞれの Network Namespace に dummy インターフェイスを追加して IP アドレスを付与する。
$ sudo ip netns exec router1 ip link add dummy0 type dummy
$ sudo ip netns exec router1 ip link set dummy0 up
$ sudo ip netns exec router1 ip address add 192.0.2.1/24 dev dummy0
$ sudo ip netns exec router2 ip link add dummy0 type dummy
$ sudo ip netns exec router2 ip link set dummy0 up
$ sudo ip netns exec router2 ip address add 198.51.100.1/24 dev dummy0
$ sudo ip netns exec router1 ping -c3203.0.113.2-I203.0.113.1
PING 203.0.113.2(203.0.113.2) from 203.0.113.1 : 56(84) bytes of data.
64 bytes from 203.0.113.2: icmp_seq=1ttl=64time=0.078 ms
64 bytes from 203.0.113.2: icmp_seq=2ttl=64time=0.071 ms
64 bytes from 203.0.113.2: icmp_seq=3ttl=64time=0.075 ms
--- 203.0.113.2 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2116ms
rtt min/avg/max/mdev =0.071/0.074/0.078/0.003 ms
また、現状では 192.0.2.1 と 198.51.100.1 の間に疎通がないことも確認する。
$ sudo ip netns exec router1 ping -c3198.51.100.1-I192.0.2.1
PING 198.51.100.1(198.51.100.1) from 192.0.2.1 : 56(84) bytes of data.
--- 198.51.100.1 ping statistics ---3 packets transmitted, 0 received, 100% packet loss, time 2096ms
$ sudo ip netns exec router1 ip route show
192.0.2.0/24 dev dummy0 proto kernel scope link src 192.0.2.1203.0.113.0/24 dev rt1-veth0 proto kernel scope link src 203.0.113.1
$ sudo ip netns exec router2 ip route show
198.51.100.0/24 dev dummy0 proto kernel scope link src 198.51.100.1203.0.113.0/24 dev rt2-veth0 proto kernel scope link src 203.0.113.2
$ sudo ip netns exec router1 ipsec verify
Verifying installed system and configuration files
Version check and ipsec on-path [OK]
Libreswan 3.32(netkey) on 5.15.0-87-generic
Checking for IPsec support in kernel [OK]
NETKEY: Testing XFRM related proc values
ICMP default/send_redirects [OK]
ICMP default/accept_redirects [OK]
XFRM larval drop [OK]
Pluto ipsec.conf syntax [OK]
Checking rp_filter [OK]
Checking that pluto is running [OK]
Pluto listening for IKE on udp 500[OK]
Pluto listening for IKE/NAT-T on udp 4500[OK]
Pluto ipsec.secret syntax [OK]
Checking 'ip'command[OK]
Checking 'iptables'command[OK]
Checking 'prelink'command does not interfere with FIPS [OK]
Checking for obsolete ipsec.conf options [OK]
$ sudo ip netns exec router2 ipsec verify
Verifying installed system and configuration files
Version check and ipsec on-path [OK]
Libreswan 3.32(netkey) on 5.15.0-87-generic
Checking for IPsec support in kernel [OK]
NETKEY: Testing XFRM related proc values
ICMP default/send_redirects [OK]
ICMP default/accept_redirects [OK]
XFRM larval drop [OK]
Pluto ipsec.conf syntax [OK]
Checking rp_filter [OK]
Checking that pluto is running [OK]
Pluto listening for IKE on udp 500[OK]
Pluto listening for IKE/NAT-T on udp 4500[OK]
Pluto ipsec.secret syntax [OK]
Checking 'ip'command[OK]
Checking 'iptables'command[OK]
Checking 'prelink'command does not interfere with FIPS [OK]
Checking for obsolete ipsec.conf options [OK]
デーモンを起動できたら ipsec auto コマンドを使って IPsec VPN のコネクションを開始する。
$ sudo ip netns exec router1 ipsec auto \--config /var/tmp/router1/ipsec.conf \--ctlsocket /var/tmp/router1/pluto.ctl \--start myvpn
コマンドを実行すると IPsec VPN のセッションが確立される。
確立されたセッションは ipsec show コマンドで確認できる。
$ sudo ip netns exec router1 ipsec show
192.0.2.0/24<=>198.51.100.0/24 using reqid 16393
$ sudo ip netns exec router2 ipsec show
198.51.100.0/24<=>192.0.2.0/24 using reqid 16389
$ sudo ip netns exec router1 ip address show ipsec0
5: ipsec0@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 203.0.113.1 peer 203.0.113.2
inet6 fe80::200:5efe:cb00:7101/64 scope link
valid_lft forever preferred_lft forever
$ sudo ip netns exec router2 ip address show ipsec0
5: ipsec0@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 203.0.113.2 peer 203.0.113.1
inet6 fe80::200:5efe:cb00:7102/64 scope link
valid_lft forever preferred_lft forever
$ sudo ip netns exec router1 ip route show
192.0.2.0/24 dev dummy0 proto kernel scope link src 192.0.2.1198.51.100.0/24 dev ipsec0 scope link
203.0.113.0/24 dev rt1-veth0 proto kernel scope link src 203.0.113.1
$ sudo ip netns exec router2 ip route show
192.0.2.0/24 dev ipsec0 scope link
198.51.100.0/24 dev dummy0 proto kernel scope link src 198.51.100.1203.0.113.0/24 dev rt2-veth0 proto kernel scope link src 203.0.113.2
$ sudo ip netns exec router1 ip tunnel add ipsec0 mode vti local203.0.113.1 remote 203.0.113.2 key 42
$ sudo ip netns exec router1 ip link set ipsec0 up
$ sudo ip netns exec router1 ip route add 198.51.100.0/24 dev ipsec0
$ sudo ip netns exec router2 ip tunnel add ipsec0 mode vti local203.0.113.2 remote 203.0.113.1 key 42
$ sudo ip netns exec router2 ip link set ipsec0 up
$ sudo ip netns exec router2 ip route add 192.0.2.0/24 dev ipsec0
動作を確認する
さて、ここまでで正常に IPsec VPN が確立されたようなので動作を確認しよう。
まずは、最初の方で確認した dummy0 インターフェイス同士の IP アドレスで疎通を確認しておく。
$ sudo ip netns exec router1 ping 198.51.100.1-I192.0.2.1
PING 198.51.100.1(198.51.100.1) from 192.0.2.1 : 56(84) bytes of data.
64 bytes from 198.51.100.1: icmp_seq=1ttl=64time=0.188 ms
64 bytes from 198.51.100.1: icmp_seq=2ttl=64time=0.266 ms
64 bytes from 198.51.100.1: icmp_seq=3ttl=64time=0.316 ms
...
続いて IKE SA と Child SA を確立している部分の通信も確認してみよう。
一旦 ping は止めておく。
そして、ipsec auto コマンドを使って VPN のコネクションを一旦削除する。
$ sudo ip netns exec router1 ipsec auto \--config /var/tmp/router1/ipsec.conf \--ctlsocket /var/tmp/router1/pluto.ctl \--delete myvpn
続いて、次のようにして IPsec と IKE の通信が確認できるように tcpdump を実行する。
$ sudo ip netns exec router1 tcpdump -tnl-i rt1-veth0 esp or udp port 500 or udp port 4500 or tcp port 4500
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on rt1-veth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
準備ができたら IPsec VPN のコネクションを次のようにして張りなおす。
$ sudo ip netns exec router1 ipsec auto \--config /var/tmp/router1/ipsec.conf \--ctlsocket /var/tmp/router1/pluto.ctl \--add myvpn
$ sudo ip netns exec router1 ipsec auto \--config /var/tmp/router1/ipsec.conf \--ctlsocket /var/tmp/router1/pluto.ctl \--start myvpn
すると tcpdump のターミナルに次のような出力が得られる。
$ sudo ip netns exec router1 tcpdump -tnl-i rt1-veth0 esp or udp port 500 or udp port 4500 or tcp port 4500
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on rt1-veth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
IP 203.0.113.1.500>203.0.113.2.500: isakmp: parent_sa ikev2_init[I]
IP 203.0.113.2.500>203.0.113.1.500: isakmp: parent_sa ikev2_init[R]
IP 203.0.113.1.500>203.0.113.2.500: isakmp: child_sa ikev2_auth[I]
IP 203.0.113.2.500>203.0.113.1.500: isakmp: child_sa ikev2_auth[R]
isakmp: parent_sa となっているのが IKE SA を確立している部分だろう。
ikev2_init[I] や ikev2_init[R] の [I] と [R] はイニシエータとレスポンダを表している。
そして isakmp: child_sa が Child SA を確立している部分のはず。
Child SA が確立されると IPsec VPN が確立されたことになる。
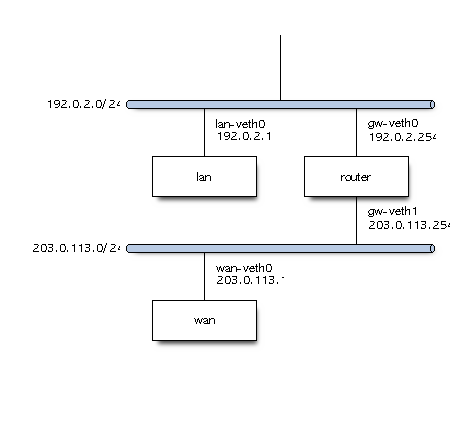
$ sudo ip netns add lan
$ sudo ip netns add router
$ sudo ip netns add wan
次に Network Namespace 同士をつなぐ veth インターフェイスを追加する。
$ sudo ip link add lan-veth0 type veth peer name gw-veth0
$ sudo ip link add wan-veth0 type veth peer name gw-veth1
作成したインターフェイスを Network Namespace に所属させる。
$ sudo ip link set lan-veth0 netns lan
$ sudo ip link set gw-veth0 netns router
$ sudo ip link set gw-veth1 netns router
$ sudo ip link set wan-veth0 netns wan
インターフェイスの状態を UP に設定する。
$ sudo ip netns exec lan ip link set lan-veth0 up
$ sudo ip netns exec router ip link set gw-veth0 up
$ sudo ip netns exec router ip link set gw-veth1 up
$ sudo ip netns exec wan ip link set wan-veth0 up
lan について、インターフェイスに IP アドレスを付与する。
また、デフォルトルートを設定する。
$ sudo ip netns exec lan ip address add 192.0.2.1/24 dev lan-veth0
$ sudo ip netns exec lan ip route add default via 192.0.2.254
router について、インターフェイスに IP アドレスを付与する。
また、ルータとして動作するようにカーネルパラメータの net.ipv4.ip_forward に 1 を設定する。
$ sudo ip netns exec router ip address add 192.0.2.254/24 dev gw-veth0
$ sudo ip netns exec router ip address add 203.0.113.254/24 dev gw-veth1
$ sudo ip netns exec router sysctl net.ipv4.ip_forward=1
最後に wan について、インターフェイスに IP アドレスを付与する。
また、デフォルトルートを設定する。
$ sudo ip netns exec wan ip address add 203.0.113.1/24 dev wan-veth0
$ sudo ip netns exec wan ip route add default via 203.0.113.254
nftables を設定する
ここからは nftables を使って Destination NAT を設定していく。
nftables の設定は nft list ruleset コマンドで確認できる。
初期状態では何も設定されていないため、結果は何も表示されない。




徹底攻略 データベーススペシャリスト教科書 令和5年度")