CUI に関しては battery というコマンドがインストールされる。
このコマンドで充電される上限を設定することもできる。
というより GUI は、この CUI の単なるラッパーのようだ。
たとえば battery status コマンドでバッテリーの充電状態を確認できたりもする。
以下は 80% に到達したことで充電が停止した際のログ。
$ battery status10/15/23-17:19:32 - Battery at 80% (attached; remaining), smc charging disabled
10/15/23-17:19:32 - Your battery is currently being maintained at 80%
上限の数値を変更したいときは battery maintain サブコマンドを使う。
$ battery maintain 70
上記を実行すると GUI で実行しているアプリの表示も変わるはず。
ちなみに上記のコマンドは、内部的に smc-command という実装を使っているようだ。
これは Mac の SMC に対して特定のキー・バリューを書き込むもの。
$ file compression.tar.gz
compression.tar.gz: gzip compressed data, was "compression.tar", last modified: Tue Aug 20 10:50:49 2023, max compression, original size modulo 2^3210240
tar(1) コマンドを使って展開してみよう。
$ tar zxvf compression.tar.gz
x compression.txt
すると compression.txt というファイルができる。
内容を確認してみよう。
$ cat compression.txt
Hello, World
ちゃんとサンプルコードで使った文字列が書き込まれている。
ちなみに、今回はアーカイブの直下にファイルを配置した。
もし、展開したときにファイルをディレクトリに入れたいときは TarInfo の引数 name にスラッシュを含めよう。
まとめ
今回は Python の tarfile モジュールを使って tar ファイルを圧縮・展開してみた。
$ gcloud functions logs read helloworld --region asia-northeast1
LEVEL NAME TIME_UTC LOG
I helloworld 2023-08-06 14:56:35.116 Default STARTUP TCP probe succeeded after 1 attempt for container "helloworld-1" on port 8080.
$ gcloud functions logs read helloworld --region asia-northeast1
LEVEL NAME TIME_UTC LOG
I helloworld 2023-08-06 14:59:00.192 successfully saved to 2023-08-06/14:58:57.log in amedama-example-bucket-20230806
I helloworld 2023-08-06 14:59:00.191
I helloworld 2023-08-06 14:58:57.341
I helloworld 2023-08-06 14:56:35.116 Default STARTUP TCP probe succeeded after 1 attempt for container "helloworld-1" on port 8080.
$ gcloud functions logs read helloworld --region asia-east1
LEVEL NAME TIME_UTC LOG
I helloworld 2023-08-06 15:48:33.154 Default STARTUP TCP probe succeeded after 1 attempt for container "helloworld-1" on port 8080.
$ gcloud functions logs read helloworld --region asia-east1
LEVEL NAME TIME_UTC LOG
I helloworld 2023-08-06 15:50:14.490 Hello, World!
I helloworld 2023-08-06 15:50:14.395
I helloworld 2023-08-06 15:50:14.260
I helloworld 2023-08-06 15:48:33.154 Default STARTUP TCP probe succeeded after 1 attempt for container "helloworld-1" on port 8080.
$ python ts.py
INFO:__main__:match David vs Bob, winner: Bob
INFO:__main__:match Charlie vs Eve, winner: Charlie
INFO:__main__:match Alice vs Frank, winner: Alice
...(省略)...
INFO:__main__:winner Bob 31.327(0.95) ->31.351(0.95), loser David 22.064(0.89) ->22.043(0.89)
INFO:__main__:winner Alice 36.249(1.08) ->36.279(1.08), loser Charlie 26.857(0.90) ->26.835(0.90)
INFO:__main__:winner Eve 18.549(0.94) ->18.623(0.94), loser Frank 14.695(1.03) ->14.606(1.03)
INFO:__main__:player Alice 36.279(1.08)
INFO:__main__:player Bob 31.351(0.95)
INFO:__main__:player Charlie 26.835(0.90)
INFO:__main__:player David 22.043(0.89)
INFO:__main__:player Eve 18.623(0.94)
INFO:__main__:player Frank 14.606(1.03)
$ python elo.py
INFO:__main__:match David vs Bob, winner: Bob
INFO:__main__:match Charlie vs Eve, winner: Charlie
INFO:__main__:match Alice vs Frank, winner: Alice
...(省略)...
INFO:__main__:winner Bob 1808 ->1811(2), loser David 1357 ->1355(-2)
INFO:__main__:winner Alice 2062 ->2064(1), loser Charlie 1584 ->1583(-1)
INFO:__main__:winner Eve 1170 ->1179(9), loser Frank 1015 ->1005(-9)
INFO:__main__:player Alice 2064
INFO:__main__:player Bob 1811
INFO:__main__:player Charlie 1583
INFO:__main__:player David 1355
INFO:__main__:player Eve 1179
INFO:__main__:player Frank 1005
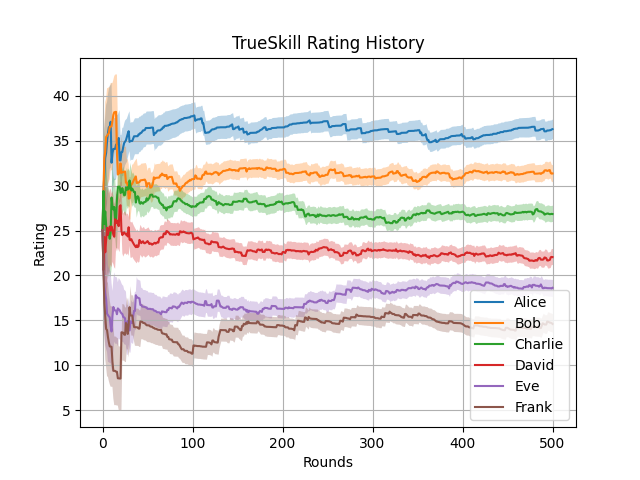
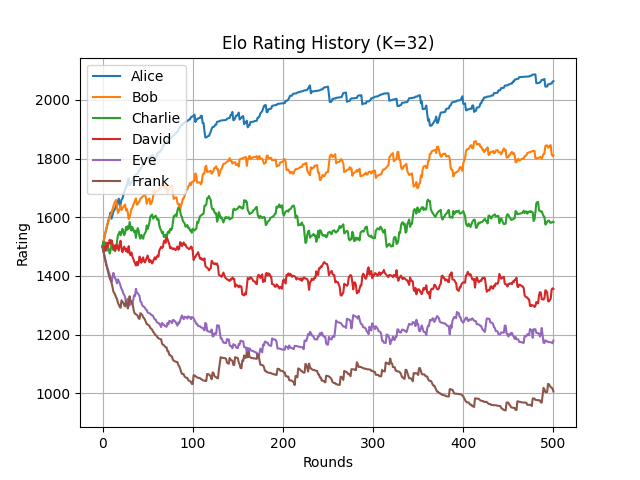
また、実行すると次のような折れ線グラフが得られる。
イロレーティングの収束する様子
上記から、理論上のレーティングに収束するまで大体 200 ラウンドほど要していることが確認できる。
収束を早くしたい場合には、レーティングを計算する際の定数 K (サンプルコードの K_FACTOR) を大きくすれば良い。
しかし、大きくすると今度はレーティングの変化も大きくなるため値が安定しにくくなるというトレードオフがある。
このトレードオフを緩和するために、最初の頃の対戦では定数を大きくしておいて、その後は小さくしていくようなテクニックもあるようだ。