イロレーティング (Elo Rating) は 2 人のプレイヤーが対戦して勝敗を決める競技において、プレイヤーの実力を数値にする手法のひとつ 1。 歴史のある古典的な手法だけど、現在でも様々な競技のレーティングに用いられている。 今回は、そんなイロレーティングをモンテカルロ法で作成した擬似的な対戦データを元に計算してみる。
使った環境は次のとおり。
$ sw_vers ProductName: macOS ProductVersion: 13.5 BuildVersion: 22G74 $ python -V Python 3.10.12 $ pip list | grep -i matplotlib matplotlib 3.7.2
もくじ
下準備
レーティングの推移を可視化するために、あらかじめ Matplotlib をインストールしておく。
$ pip install matplotlib
サンプルコード
これから示すサンプルコードは 2 つのフェーズに分かれている。
- 理論上のイロレーティングを与えたプレイヤーからモンテカルロ法で擬似的な対戦データを作成するフェーズ
- 作成した擬似的な対戦データからイロレーティングの推移を計算して収束する様子を観察するフェーズ
まず、1. についてはイロレーティングが理論上の対戦勝率を計算できる点を利用している。 あらかじめ特定の値でイロレーティングを指定したプレイヤー同士をランダムに対戦させて、その勝率が疑似乱数を上回るかどうかで作成する。
そして 2. については、1. で作成した疑似データを使って、各プレイヤーが初期値の状態からイロレーティングの数値を更新していく。 このとき、疑似データが十分にあれば、理論上のイロレーティングに収束していくはずである。
なお 1. の疑似データは Alice, Bob, Charlie, David, Eve, Frank という名前をつけた 6 人のプレイヤーから生成する。 6 人のプレイヤーは各ラウンドでランダムにシャッフルされて 2 人ずつ対戦する。 対戦した際の勝者は、前述したとおり事前に規定したイロレーティングと疑似乱数にもとづいて計算される。
以下にサンプルコードを示す。 各プレイヤーは 200 刻みで理論上のイロレーティングを付与している。 そして、500 回のラウンドを実施する。 各ラウンドは 3 回の対戦が含まれるため、全体で 1,500 回の対戦が生じる。
import logging import random from matplotlib import pyplot as plt LOG = logging.getLogger(__name__) # レーティングが更新される大きさを表す K ファクター K_FACTOR = 32 class Player: """プレイヤーを表現したクラス""" def __init__(self, rating=1500): self.rating = rating def win_proba(self, other_player: "Player") -> float: """他のプレイヤーに勝利する確率を計算するメソッド""" return 1. / (10. ** ((other_player.rating - self.rating) / 400.) + 1.) def simulated_match(player_a: Player, player_b: Player) -> bool: """モンテカルロ法でプレイヤー同士を対決させる :returns: シミュレーションで player_a が勝利したかを表す真偽値 """ player_a_win_ratio = player_a.win_proba(player_b) return random.random() < player_a_win_ratio def update_rating(winner: Player, loser: Player) -> tuple[Player, Player]: """対戦成績を元にレーティングを更新する""" new_winner_rating = winner.rating + K_FACTOR * loser.win_proba(winner) new_loser_rating = loser.rating - K_FACTOR * loser.win_proba(winner) return Player(new_winner_rating), Player(new_loser_rating) def main(): # ログレベルを設定する logging.basicConfig(level=logging.INFO) # 乱数シードを固定する random.seed(42) # プレイヤーの理論上のレーティング ideal_players = { "Alice": Player(2000), "Bob": Player(1800), "Charlie": Player(1600), "David": Player(1400), "Eve": Player(1200), "Frank": Player(1000), } # モンテカルロ法で対戦履歴を生成する match_results = [] for _ in range(500): # プレイヤーをシャッフルする shuffled_player_names = random.sample( list(ideal_players.keys()), len(ideal_players), ) while len(shuffled_player_names) > 0: # シャッフルした結果から 1 vs 1 を取り出していく player_a_name, player_b_name = shuffled_player_names.pop(), shuffled_player_names.pop() player_a, player_b = ideal_players[player_a_name], ideal_players[player_b_name] # レーティングとランダムな値を元に対戦結果を求める win_player_name = player_a_name if simulated_match(player_a, player_b) else player_b_name match_results.append((player_a_name, player_b_name, win_player_name)) # 対戦成績をログに出力する LOG.info( "match %s vs %s, winner: %s", player_a_name, player_b_name, win_player_name, ) # プレイヤーのレーティング履歴 simulated_players = { "Alice": [Player()], "Bob": [Player()], "Charlie": [Player()], "David": [Player()], "Eve": [Player()], "Frank": [Player()], } # 対戦成績を 1 件ずつ処理する for player_a_name, player_b_name, win_player_name in match_results: # 勝利プレイヤーと敗北プレイヤーの名前を取り出す winner_name = win_player_name loser_name = player_b_name if win_player_name == player_a_name else player_a_name # 履歴で最後 (最新) のレーティングを取り出す winner = simulated_players[winner_name][-1] loser = simulated_players[loser_name][-1] # 対戦成績を元にレーティングを更新する updated_winner, updated_loser = update_rating(winner, loser) # 履歴の末尾に追加する simulated_players[winner_name].append(updated_winner) simulated_players[loser_name].append(updated_loser) # レーティングの更新をログに出力する LOG.info( "winner %s %d -> %d (%d), loser %s %d -> %d (%d)", winner_name, winner.rating, updated_winner.rating, updated_winner.rating - winner.rating, loser_name, loser.rating, updated_loser.rating, updated_loser.rating - loser.rating, ) # 最終的なレーティングをログに出力する for player_name, player_history in simulated_players.items(): LOG.info("player %s %d", player_name, player_history[-1].rating) # レーティングの推移を折れ線グラフで可視化する fig, ax = plt.subplots(1, 1) for player_name, player_history in simulated_players.items(): player_rating_history = [player.rating for player in player_history] ax.plot(player_rating_history, label=player_name) ax.set_title(f"Elo Rating History (K={K_FACTOR})") ax.set_xlabel("Rounds") ax.set_ylabel("Rating") ax.grid() ax.legend() plt.show() if __name__ == "__main__": main()
上記を実行してみよう。 最初に出力されるログがモンテカルロ法で作成した擬似的な対戦データで、次に出力されるのが対戦成績にもとづいてイロレーティングが更新される様子になる。
$ python elo.py INFO:__main__:match David vs Bob, winner: Bob INFO:__main__:match Charlie vs Eve, winner: Charlie INFO:__main__:match Alice vs Frank, winner: Alice ...(省略)... INFO:__main__:winner Bob 1808 -> 1811 (2), loser David 1357 -> 1355 (-2) INFO:__main__:winner Alice 2062 -> 2064 (1), loser Charlie 1584 -> 1583 (-1) INFO:__main__:winner Eve 1170 -> 1179 (9), loser Frank 1015 -> 1005 (-9) INFO:__main__:player Alice 2064 INFO:__main__:player Bob 1811 INFO:__main__:player Charlie 1583 INFO:__main__:player David 1355 INFO:__main__:player Eve 1179 INFO:__main__:player Frank 1005
また、実行すると次のような折れ線グラフが得られる。
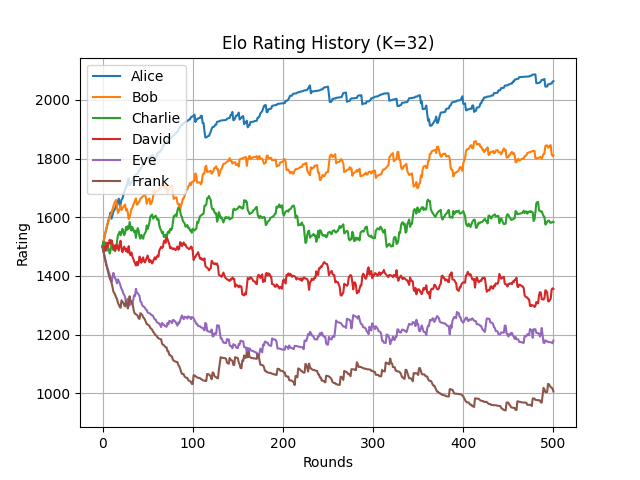
上記から、理論上のレーティングに収束するまで大体 200 ラウンドほど要していることが確認できる。
収束を早くしたい場合には、レーティングを計算する際の定数 K (サンプルコードの K_FACTOR) を大きくすれば良い。
しかし、大きくすると今度はレーティングの変化も大きくなるため値が安定しにくくなるというトレードオフがある。
このトレードオフを緩和するために、最初の頃の対戦では定数を大きくしておいて、その後は小さくしていくようなテクニックもあるようだ。
いじょう。

- 1 対 1 の対戦でさえあれば、複数人のチームであっても構わない↩