以前、このブログでは機械学習モデルの解釈可能性を向上させる手法として SHAP を扱った。
上記のエントリでは、LightGBM の train() 関数と共に、モデルの学習に使ったデータを解釈していた。
今度は cv() 関数を使って、Out-of-Fold なデータを解釈する例を試してみる。
つまり、モデルにとって未知のデータを、どのような根拠で予測をしているのかざっくり把握することが目的になる。
使った環境は次のとおり。
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.7 BuildVersion: 19H114 $ python -V Python 3.8.6
もくじ
下準備
あらかじめ、必要なパッケージをインストールしておく。
$ pip install -U "lightgbm>3" shap scikit-learn pandas matplotlib
擬似的な二値分類用のデータを作って試してみる
前回のエントリと同じように、scikit-learn の API を使って擬似的な二値分類用のデータを作って試してみよう。 データは 100 次元あるものの、先頭の 5 次元しか分類には寄与する特徴になっていない。
サンプルコードを以下に示す。
基本的には cv() 関数から取り出した CVBooster を使って、Out-of-Fold な Prediction を作る要領で SHAP Value を計算するだけ。
あとは、それを好きなように可視化していく。
以下では、CVBooster を構成している各 Booster について summary_plot() で可視化した。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import numpy as np import pandas as pd import shap import lightgbm as lgb from sklearn.datasets import make_classification from sklearn.model_selection import StratifiedKFold from matplotlib import pyplot as plt def main(): # 疑似的な教師信号を作るためのパラメータ args = { # データ点数 'n_samples': 10_000, # 次元数 'n_features': 100, # その中で意味のあるもの 'n_informative': 5, # 重複や繰り返しはなし 'n_redundant': 0, 'n_repeated': 0, # タスクの難易度 'class_sep': 0.65, # 二値分類問題 'n_classes': 2, # 生成に用いる乱数 'random_state': 42, # 特徴の順序をシャッフルしない (先頭の次元が informative になる) 'shuffle': False, } # 擬似的な二値分類用の教師データを作る dummy_x, dummy_y = make_classification(**args) # 一般的なユースケースを想定して Pandas のデータフレームにしておく col_names = [f'feature_{i:02d}' for i in range(dummy_x.shape[1])] df = pd.DataFrame(data=dummy_x, columns=col_names) df['target'] = pd.Series(data=dummy_y, dtype=bool) # 教師データ train_x, train_y = df.drop(['target'], axis=1), df.target # データの分割方法は Stratified 5-Fold CV folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=42, ) # LightGBM のデータセット形式にする lgb_train = lgb.Dataset(train_x, train_y) # 学習時のパラメータ lgb_params = { 'objective': 'binary', 'metric': 'binary_logloss', 'first_metric_only': True, 'verbose': -1, } # 学習する cv_result = lgb.cv(params=lgb_params, train_set=lgb_train, folds=folds, num_boost_round=10_000, early_stopping_rounds=100, verbose_eval=10, return_cvbooster=True, ) # CVBooster を取り出す cvbooster = cv_result['cvbooster'] # Out-of-Fold なデータで SHAP Value を計算する split_indices = list(folds.split(train_x, train_y)) cv_shap_values = np.zeros_like(train_x, dtype=np.float) # Booster と学習に使ったデータの対応関係を取る booster_split_mappings = list(zip(cvbooster.boosters, split_indices)) for booster, (_, val_index) in booster_split_mappings: # Booster が学習に使っていないデータ booster_val_x = train_x.iloc[val_index] # SHAP Value を計算する explainer = shap.TreeExplainer(booster, model_output='probability', data=booster_val_x) train_x_shap_values = explainer.shap_values(booster_val_x) cv_shap_values[val_index] = train_x_shap_values # 各教師データに対応する SHAP Value さえ計算できれば、後は好きに可視化すれば良い # 試しに各 Booster の summary_plot を眺めてみる plt.figure(figsize=(12, 16)) for i, (_, val_index) in enumerate(split_indices): # 描画位置 plt.subplot(3, 2, i + 1) # 各 Booster の Explainer が出力した SHAP Value ごとにプロットしていく shap.summary_plot(shap_values=cv_shap_values[val_index], features=train_x.iloc[val_index], feature_names=train_x.columns, plot_size=None, show=False) plt.title(f'Booster: {i}') plt.show() # 1 つのグラフにするなら、これだけで良い """ shap.summary_plot(shap_values=cv_shap_values, features=train_x, feature_names=train_x.columns) """ if __name__ == '__main__': main()
上記を保存したら、実行してみよう。 パフォーマンス的には、SHAP Value の計算部分を並列化すると、もうちょっと速くできそう。
$ python lgbcvshap.py [10] cv_agg's binary_logloss: 0.417799 + 0.00797668 [20] cv_agg's binary_logloss: 0.333266 + 0.0108777 [30] cv_agg's binary_logloss: 0.30215 + 0.0116352 ...(省略)... [220] cv_agg's binary_logloss: 0.282142 + 0.0185382 [230] cv_agg's binary_logloss: 0.283128 + 0.0188667 [240] cv_agg's binary_logloss: 0.284197 + 0.0195125 98%|===================| 1951/2000 [00:29<00:00]
実行すると、次のようなプロットが得られる。
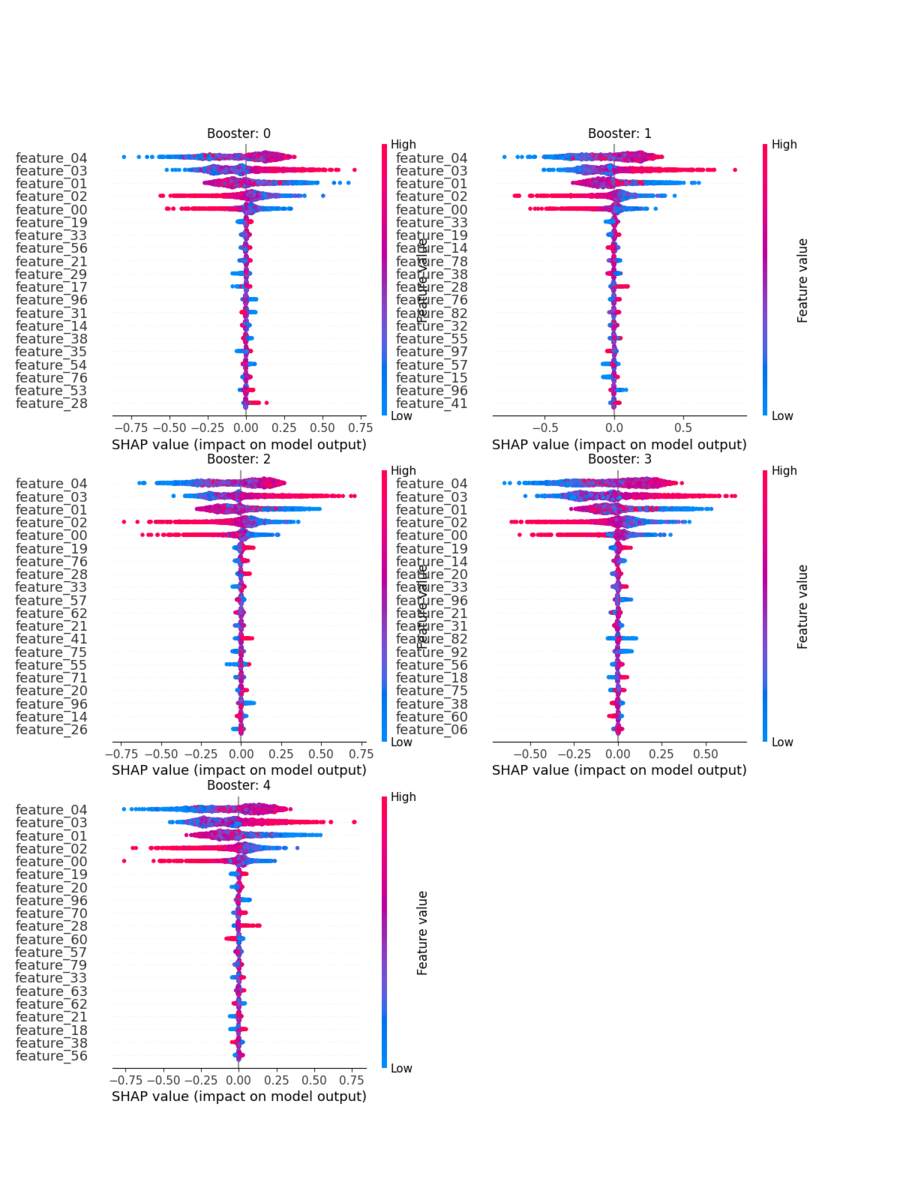
基本的には、どの Booster の結果も、先頭 5 次元の SHAP Value が大きくなっていることが見て取れる。
いじょう。

- 作者:もみじあめ
- 発売日: 2020/02/29
- メディア: Kindle版