今回は、PyTorch でオプティマイザを自作する方法について紹介してみる。
きっかけは、勉強がてら主要なオプティマイザを自作してみようと思い至ったことだった。 その過程で、PyTorch でオプティマイザを自作する場合の流儀が把握できた。
そこで、この記事では以下のオプティマイザを書きながらその方法を説明してみる。
- 単純な SGD (Stochastic Gradient Descent)
- Momentum を導入した SGD
上記は最も古典的なオプティマイザだけど、実装することで基本的な機能を一通り紹介できるため。
使った環境は次のとおり。
$ sw_vers ProductName: macOS ProductVersion: 14.6.1 BuildVersion: 23G93 $ python -V Python 3.11.9 $ pip list | grep -i torch torch 2.4.0
もくじ
下準備
まずは PyTorch をインストールしておく。
$ pip install torch matplotlib
題材とする問題について
まず、オプティマイザを扱う以上は、最適化したい何らかの問題が必要になる。
今回の記事で題材とするのは f(x, y) = ax^2 + by^2 という関数にする。
関数には定数 a, b と変数 x, y が含まれる。
そして、これらの定数と変数を適当な値で初期化した上で、結果がゼロに近づくように最適化する。
上記の問題を、まずは PyTorch に組み込みで用意された SGD の実装を使って最適化してみよう。 要するに、まずはお手本となる結果を確認する。
サンプルコードは以下のとおり。
ExampleFunction というクラスが最適化したい関数を表している。
このクラスは nn.Module を継承しており、forward() メソッドで f(x, y) = ax^2 + by^2 に相当する順伝播を実装している。
コードでは、学習率 0.95 の SGD を使うことで、この関数の出力をゼロに近づけるようにパラメータを更新する。
また、更新のイテレーション回数は 30 回に決め打ちしている。
ちなみに、この問題設定や初期値などは「ゼロから作るDeep Learning 1」に記載されている内容と同一にしている。
import torch from matplotlib import pyplot as plt from torch import nn from torch import optim class ExampleFunction(nn.Module): """最適化したい関数: f(x, y) = ax^2 + by^2""" def __init__(self, a, x, b, y): super(ExampleFunction, self).__init__() self.a = a self.x = nn.Parameter(torch.tensor([x], dtype=torch.float32)) self.b = b self.y = nn.Parameter(torch.tensor([y], dtype=torch.float32)) def forward(self): # f(x, y) = ax^2 + by^2 return self.a * self.x**2 + self.b * self.y**2 def main(): # 初期値を指定して最適化したいモデルをインスタンス化する model = ExampleFunction(a=1 / 20, x=-7.0, b=1.0, y=2.0) # SGD で最適化する optimizer = optim.SGD(model.parameters(), lr=0.95) # パラメータの軌跡を残す trajectory_x = [model.x.detach().numpy()[0]] trajectory_y = [model.y.detach().numpy()[0]] # 最適化のループを 30 回にわたって回す num_epochs = 30 for epoch in range(1, num_epochs + 1): # 勾配を初期化する optimizer.zero_grad() # モデルの出力を得る outputs = model() # 誤差逆伝搬 # 本来は損失関数を元に勾配を求める # 今回はパラメータがゼロへ近づくように最適化する outputs.backward() # パラメータを更新する optimizer.step() # 更新されたパラメータを記録する x = model.x.detach().numpy()[0] trajectory_x.append(x) y = model.y.detach().numpy()[0] trajectory_y.append(y) # パラメータのたどった軌跡を可視化する fig, ax = plt.subplots(1, 1, figsize=(8, 6)) ax.plot(trajectory_x, trajectory_y, marker="o", markersize=5, label="Trajectory") ax.legend() ax.grid(True) ax.set_xlabel("x") ax.set_ylabel("y") plt.show() if __name__ == "__main__": main()
上記に適当な名前をつけて実行してみよう。
$ python sgd.py
すると、次のようなグラフが得られる。
これは最適化の過程でパラメータの x と y が更新されていく軌跡を表している。

上記から、それぞれのパラメータが 0 に近づいていく様子が確認できる。
SGD のオプティマイザを自作する
続いては、今回の本題となるオプティマイザの自作に入る。 初めに目指すところは、PyTorch 組み込みの SGD と全く同じ結果が得られるオプティマイザを作ること。
早速だけどサンプルコードを以下に示す。
このコードでは CustomSGD という名前でオプティマイザを実装している。
以降は、この CustomSGD について順を追って説明していく。
from collections.abc import Iterable import torch from matplotlib import pyplot as plt from torch import nn from torch import optim from torch.optim import Optimizer class ExampleFunction(nn.Module): def __init__(self, a, x, b, y): super(ExampleFunction, self).__init__() self.a = a self.x = nn.Parameter(torch.tensor([x], dtype=torch.float32)) self.b = b self.y = nn.Parameter(torch.tensor([y], dtype=torch.float32)) def forward(self): return self.a * self.x**2 + self.b * self.y**2 class CustomSGD(Optimizer): """自作した SGD のオプティマイザ PyTorch でオプティマイザを自作する場合は torch.optim.Optimizer を継承する """ def __init__(self, params: Iterable, lr: float = 1e-3): # 最適化したいパラメータと、動作に必要なハイパーパラメータをスーパークラスの __init__() に渡す defaults = dict( lr=lr, ) super(CustomSGD, self).__init__(params, defaults) def step(self, closure: None = None) -> None: """SGD の更新式を実装した step() メソッド (SGD の更新式) theta_{t+1} = theta_t - eta_t * grad(L(theta_t)) theta: パラメータ (重み) eta: 学習率 grad(L(theta)): 損失関数の勾配 """ # 複数のパラメータが辞書形式で渡された際には param_groups に分割して入る for group in self.param_groups: # グループには最適化したいパラメータや、動作に必要な設定が辞書形式で入っている for param in group["params"]: # 各パラメータごとに処理していく if param.grad is None: # パラメータの勾配が計算されていないものは更新しない continue # group に格納された学習率 (lr) と勾配を使ってパラメータの値を更新する param.data -= group["lr"] * param.grad def main(): model = ExampleFunction(a=1 / 20, x=-7.0, b=1.0, y=2.0) # 自作した SGD で最適化する optimizer = CustomSGD(model.parameters(), lr=0.95) trajectory_x = [model.x.detach().numpy()[0]] trajectory_y = [model.y.detach().numpy()[0]] num_epochs = 30 for epoch in range(1, num_epochs + 1): optimizer.zero_grad() outputs = model() outputs.backward() optimizer.step() x = model.x.detach().numpy()[0] trajectory_x.append(x) y = model.y.detach().numpy()[0] trajectory_y.append(y) fig, ax = plt.subplots(1, 1, figsize=(8, 6)) ax.plot(trajectory_x, trajectory_y, marker="o", markersize=5, label="Trajectory") ax.legend() ax.grid(True) ax.set_xlabel("x") ax.set_ylabel("y") plt.show() if __name__ == "__main__": main()
まず、PyTorch でオプティマイザを作る場合には基本的に torch.optim.Optimizer を継承したクラスを作る。
その上で、実装する必要があるメソッドは __init__() と step() の 2 つある。
__init__() メソッドについて
__init__() では、オプティマイザを初期化する。
このとき、最適化したいモデルのパラメータ (重み) と動作に必要なハイパーパラメータを辞書の形式で引数としてスーパークラスの __init__() を呼び出す。
詳しくは後述するものの、こうすることで torch.optim.Optimizer で実装されているインスタンス変数などがセットアップされて利用できるようになる。
step() メソッドについて
step() メソッドは、最適化する対象のパラメータの勾配を計算した上でユーザのコードから呼び出される。
こちらに、具体的なパラメータを更新する処理を記述する。
ちなみに、ドキュメントやソースコードを確認すると、定義する上でメソッドのシグネチャは以下の 3 通りから選べるようになっている。
def step(self, closure: None = ...) -> None: def step(self, closure: Callable[[], float]) -> float: def step(self, closure: Optional[Callable[[], float]] = None) -> Optional[float]:
異なるシグネチャが存在する理由は、アルゴリズムによって引数の closure を利用するかが選べるため。
一番上のシグネチャでは closure をまったく使用しないパターン、真ん中が必ず使用するパターン、一番下があってもなくてもどちらも許容するパターンになっている。
この closure という引数には、Callable[[], float] というタイプヒントから分かるように引数なしの呼び出し可能オブジェクトが渡される。
これは最適化するモデルの損失を float 型で返すもので、オプティマイザ内で損失を評価しながら何度もパラメータを更新する場合に使用するらしい。
ただし、実際に closure を有効に使用しているアルゴリズムはごく限られている (LBFGS など) ことから、通常は一番上か一番下を選択すれば良い。
PyTorch が組み込みで実装しているオプティマイザの多くは一番下のシグネチャを選択しているようだ 2。
今回のサンプルコードではシンプルさを優先して一番上を採用した。
続いては step() メソッドの具体的な実装方法について解説していく。
前述したスーパークラスの __init__() に渡された引数は、グループ単位で Optimizer#param_groups というメンバ変数に登録される。
ここでいうグループというのは、一つの Optimizer で異なる複数の最適化を同時に実行する場合に用いられる処理のまとまりのこと。
以下のコードでは、グループをループで取り出しながら処理している。
ちなみに、通常であればここには一つの要素しか入らない。
# 複数のパラメータが辞書形式で渡された際には param_groups に分割して入る for group in self.param_groups:
グループを取り出したら、そこに辞書形式でパラメータや動作に必要な設定が入っている。
たとえば最適化の対象になるパラメータは "params" というキーで得られる。
以下のコードでは各パラメータを取り出して for ループでそれぞれ処理している。
ここでいうパラメータというのは、今回のタスクであれば x や y に当たる。
# グループには最適化したいパラメータや、動作に必要な設定が辞書形式で入っている for param in group["params"]:
パラメータによっては勾配が計算されていないことが想定される。 その場合には値を更新する必要がないというかできないので処理をスキップする。
if param.grad is None: # パラメータの勾配が計算されていないものは更新しない continue
そして、肝心の SGD の更新式を実装している部分に入る。 まず、SGD の更新式は以下のとおり。
上記の数式と、プログラムの変数の対応を以下に示す。
学習率はスーパークラスの __init__() に defaults を通して渡したことでグループに登録されている。
param.data
group["lr"]
param.grad
上記より、パラメータの更新は次のようなコードになる。
# group に格納された学習率 (lr) と勾配を使ってパラメータの値を更新する param.data -= group["lr"] * param.grad
サンプルコードを実行する
一通り説明できたので、サンプルコードに適当な名前をつけて実行する。
$ python customsgd.py
すると、以下のようなグラフが得られる。

上記から、先ほど実行した PyTorch 組み込みの SGD と全く同じ軌跡を辿っていることが確認できる。
複数のモデルを登録してみる
先ほどの例ではグループが一つしかない場合だった。 続いては、一つのオプティマイザに複数のモデルを登録する場合も試してみよう。
サンプルコードが以下になる。
このコードでは model1 と model2 という 2 つの最適化すべきモデルを一つのオプティマイザに登録している。
from collections.abc import Iterable from typing import Any import torch from matplotlib import pyplot as plt from torch import nn from torch.optim import Optimizer class ExampleFunction(nn.Module): def __init__(self, a, x, b, y): super(ExampleFunction, self).__init__() self.a = a self.x = nn.Parameter(torch.tensor([x])) self.b = b self.y = nn.Parameter(torch.tensor([y])) def forward(self): return self.a * self.x**2 + self.b * self.y**2 class CustomSGD(Optimizer): def __init__(self, params: Iterable, lr: float = 1e-3): defaults: dict[str, Any] = dict( lr=lr, ) super(CustomSGD, self).__init__(params, defaults) def step(self, closure: None = None) -> None: for group in self.param_groups: for param in group["params"]: if param.grad is None: continue param.data -= group["lr"] * param.grad def main(): # 最適化したい複数のモデル model1 = ExampleFunction(a=1 / 20, x=-7.0, b=1.0, y=2.0) model2 = ExampleFunction(a=4, x=2.0, b=3, y=2.0) # 複数のモデルを一つのオプティマイザで最適化したい場合は、それぞれを辞書として渡す # 結果は torch.optim.Optimizer#param_groups の各要素として入る optimizer = CustomSGD( [ { "params": model1.parameters(), "lr": 0.95, }, { "params": model2.parameters(), "lr": 0.05, }, ] ) # それぞれの軌跡を残す trajectory_x1 = [model1.x.detach().numpy()[0]] trajectory_y1 = [model1.y.detach().numpy()[0]] trajectory_x2 = [model2.x.detach().numpy()[0]] trajectory_y2 = [model2.y.detach().numpy()[0]] num_epochs = 30 for epoch in range(1, num_epochs + 1): optimizer.zero_grad() outputs1 = model1() outputs1.backward() outputs2 = model2() outputs2.backward() optimizer.step() x1 = model1.x.detach().numpy()[0] trajectory_x1.append(x1) y1 = model1.y.detach().numpy()[0] trajectory_y1.append(y1) x2 = model2.x.detach().numpy()[0] trajectory_x2.append(x2) y2 = model2.y.detach().numpy()[0] trajectory_y2.append(y2) # 軌跡を可視化する fig, ax = plt.subplots(1, 1, figsize=(8, 6)) ax.plot(trajectory_x1, trajectory_y1, marker="o", markersize=5, label="Trajectory1") ax.plot(trajectory_x2, trajectory_y2, marker="o", markersize=5, label="Trajectory2") ax.legend() ax.grid(True) ax.set_xlabel("x") ax.set_ylabel("y") plt.show() if __name__ == "__main__": main()
オプティマイザに登録している部分は以下のとおり。 リストの中に辞書形式で、複数のパラメータと学習率を登録している。
# 複数のパラメータを最適化したい場合は、それぞれを辞書として渡す # 結果は torch.optim.Optimizer#param_groups の各要素として入る optimizer = CustomSGD( [ { "params": model1.parameters(), "lr": 0.95, }, { "params": model2.parameters(), "lr": 0.05, }, ] )
上記のサンプルコードに名前をつけて実行してみる。
$ python groupsgd.py
すると、次のようなグラフが得られる。 異なる色の線が、それぞれのモデルのパラメータが更新されていく軌跡を表している。

上記から、それぞれのパラメータが 0 に向かって更新されていく様子が確認できる。
Momentum を導入した SGD を実装する
続いては SGD に Momentum の概念を導入する。 Momentum ではパラメータの更新にそれまでの勢いが加味されることから局所最適解に陥りにくくなる効果が見込める。
ここでは Momentum の実装を通して、オプティマイザで状態を表す変数の使い方を紹介したい。 というのも、先ほど実装した単純な SGD の更新式にはモデルのパラメータ以外に変数がなく、学習率も定数に過ぎなかった。 一方で Momentum では慣性を扱うことから、それまでのパラメータの更新のされ方を記録しておく必要がある。
早速だけど以下にサンプルコードを示す。
CustomMomentumSGD というクラスで Momentum を導入した SGD を実装している。
問題設定などは先ほどと変わらない。
ポイントは CustomMomentumSGD の step() メソッドの中で self.state というインスタンス変数を扱っているところ。
これを使うことで、オプティマイザに状態を持たせることができる。
from collections.abc import Iterable from typing import Any import torch from matplotlib import pyplot as plt from torch import nn from torch.optim import Optimizer class ExampleFunction(nn.Module): def __init__(self, a, x, b, y): super(ExampleFunction, self).__init__() self.a = a self.x = nn.Parameter(torch.tensor([x])) self.b = b self.y = nn.Parameter(torch.tensor([y])) def forward(self): return self.a * self.x**2 + self.b * self.y**2 class CustomMomentumSGD(Optimizer): """自作した Momentum SGD のオプティマイザ""" def __init__(self, params: Iterable, lr: float = 1e-3, momentum: float = 0.9): defaults: dict[str, Any] = dict( lr=lr, momentum=momentum, ) super(CustomMomentumSGD, self).__init__(params, defaults) def step(self, closure: None = None) -> None: """Momentum を導入した SGD の更新式を実装した step() メソッド (更新式) v_0 = 0 v_{t+1} = gamma * v_t + grad(L(theta_t)) theta_{t+1} = theta_t - eta * v_{t+1} theta: パラメータ (重み) gamma: モーメンタム係数 v: モーメント eta: 学習率 grad(L(theta)): 損失関数の勾配 """ for group in self.param_groups: for param in group["params"]: if param.grad is None: continue # v_0 = 0 に対応している if "v" not in self.state[param]: # モーメントが存在しない初期状態であればゼロで初期化する self.state[param]["v"] = torch.zeros_like(param.data) # v_{t+1} = gamma * v_t + grad(L(theta_t)) に対応している self.state[param]["v"] = ( group["momentum"] * self.state[param]["v"] + param.grad ) # theta_{t+1} = theta_t - eta * v_{t+1} に対応している param.data -= group["lr"] * self.state[param]["v"] def main(): model = ExampleFunction(a=1 / 20, x=-7.0, b=1.0, y=2.0) # 自作した Momentum SGD で最適化する optimizer = CustomMomentumSGD(model.parameters(), lr=0.1, momentum=0.9) trajectory_x = [model.x.detach().numpy()[0]] trajectory_y = [model.y.detach().numpy()[0]] num_epochs = 30 for epoch in range(1, num_epochs + 1): optimizer.zero_grad() outputs = model() outputs.backward() optimizer.step() x = model.x.detach().numpy()[0] trajectory_x.append(x) y = model.y.detach().numpy()[0] trajectory_y.append(y) fig, ax = plt.subplots(1, 1, figsize=(8, 6)) ax.plot(trajectory_x, trajectory_y, marker="o", markersize=5, label="Trajectory") ax.legend() ax.grid(True) ax.set_xlabel("x") ax.set_ylabel("y") plt.show() if __name__ == "__main__": main()
以降は単純な SGD との違いについて __init__() メソッドと step() のコードを見ていく。
__init__() メソッドについて
まず、__init__() では momentum という名前で float 型の引数が増えている。
これは、パラメータが更新される際の慣性の強さを指定するハイパーパラメータになっている。
この引数の値が大きいほど、それまでの勢いが強く反映された状態でパラメータが更新される。
学習率 (lr) と同じように、スーパークラスの __init__() に渡すことで group["momentum"] という形式でアクセスできるようになる。
step() メソッドについて
続いては step() メソッドについて。
このメソッドは Momentum を導入した SGD の更新式と共に見ていこう。
更新式は次のとおり。
上記の数式と、プログラムの変数の対応を以下に示す。
SGD に比べると と
が増えている。
前述した通り
self.state を使って「勢い」を状態として保持する。
param.data
group["lr"]
param.grad
group["momentum"]
self.state[param]["v"]
はじめに以下の更新式に対応するコードから。
ここでは、要するに最初は状態が何もないので必要な変数をゼロで初期化している。
if "v" not in self.state[param]: # モーメントが存在しない初期状態であればゼロで初期化する self.state[param]["v"] = torch.zeros_like(param.data)
次に、以下の更新式に対応するコード。
ここでは過去の更新の勢いを加味しながら、新しい勾配を使って次の更新のされ方を決めている。 こういった、過去の値に係数をかけつつ新しい値を足していくやり方は指数移動平均と呼ばれる。 主要なオプティマイザのアルゴリズムでは、この指数移動平均の処理が頻出する。
self.state[param]["v"] = group["momentum"] * self.state[param]["v"] + param.grad
最後に、以下の更新式に対応するコード。
ここでは、先ほどのモーメントに学習率をかけたもので実際のパラメータを更新している。
param.data -= group["lr"] * self.state[param]["v"]
サンプルコードを実行する
一通り説明できたので、サンプルコードに適当な名前をつけて実行する。
$ python custommomentum.py
すると、以下のようなグラフが得られる。

単純な SGD とはアルゴリズムやハイパーパラメータが異なることから、パラメータの軌跡も異なることが確認できる。
PyTorch 組み込みの結果と比べる
念の為、PyTorch に組み込みで用意されている Momentum SGD と結果が揃うことを確認する。
サンプルコードは次のとおり。 オプティマイザを組み込みのものに差し替えた以外の違いはない。
from collections.abc import Iterable from typing import Any import torch from matplotlib import pyplot as plt from torch import nn from torch import optim from torch.optim import Optimizer class ExampleFunction(nn.Module): def __init__(self, a, x, b, y): super(ExampleFunction, self).__init__() self.a = a self.x = nn.Parameter(torch.tensor([x])) self.b = b self.y = nn.Parameter(torch.tensor([y])) def forward(self): return self.a * self.x**2 + self.b * self.y**2 def main(): model = ExampleFunction(a=1 / 20, x=-7.0, b=1.0, y=2.0) # PyTorch 組み込みの Momentum SGD で最適化する # SGD の引数に momentum を指定するだけ optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9) trajectory_x = [model.x.detach().numpy()[0]] trajectory_y = [model.y.detach().numpy()[0]] num_epochs = 30 for epoch in range(1, num_epochs + 1): optimizer.zero_grad() outputs = model() outputs.backward() optimizer.step() x = model.x.detach().numpy()[0] trajectory_x.append(x) y = model.y.detach().numpy()[0] trajectory_y.append(y) fig, ax = plt.subplots(1, 1, figsize=(8, 6)) ax.plot(trajectory_x, trajectory_y, marker="o", markersize=5, label="Trajectory") ax.legend() ax.grid(True) ax.set_xlabel("x") ax.set_ylabel("y") plt.show() if __name__ == "__main__": main()
上記に適当な名前をつけて実行する。
$ python torchmomentum.py
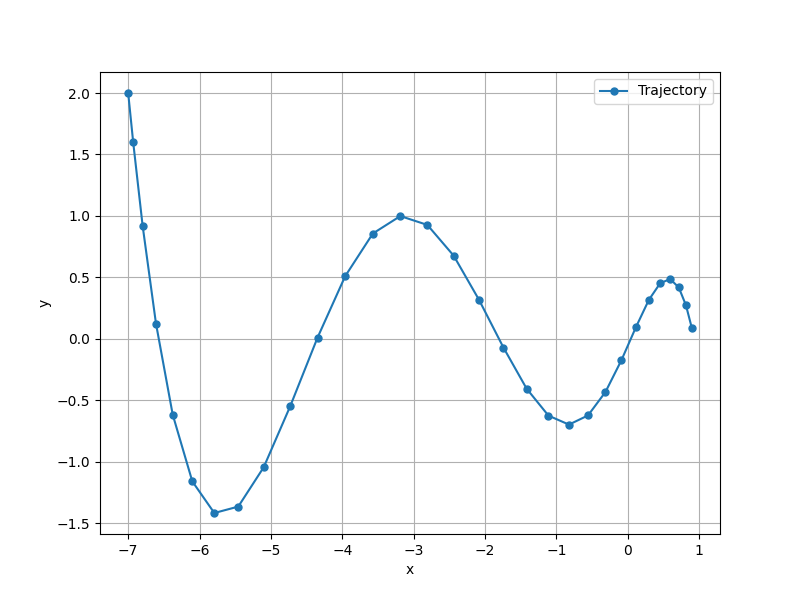
自作した Momentum SGD と軌跡が一致していることが確認できる。
まとめ
今回は PyTorch でオプティマイザを自作する方法について紹介した。
参考
SGD と Momentum SGD の更新式は、以下の論文に記載されている内容を参考にした。

- https://www.oreilly.co.jp/books/9784873117584/↩
-
ただし
closureが登録されているときは損失を受け取って、それをただメソッドの返り値にしているだけ↩