Prophet は Meta (旧 Facebook) が中心となって開発している OSS の時系列予測フレームワーク。 目的変数のトレンド、季節性、イベントや外部説明変数を加味した時系列予測を簡単にできることが特徴として挙げられる。 使い所としては、精度はさほど追求しない代わりにとにかく手軽に予測がしたい、といった場面が考えられる。 また、扱うデータセットについても単変量に近いシンプルなものが得意そう。 なお、今回は扱うデータセットの都合からイベントや外部説明変数の追加に関しては扱わない。
使った環境は次のとおり。
$ sw_vers ProductName: macOS ProductVersion: 12.2.1 BuildVersion: 21D62 $ uname -srm Darwin 21.3.0 arm64 $ python -V Python 3.9.10 $ pip list | grep -i prophet prophet 1.0.1
もくじ
下準備
あらかじめ Prophet をインストールしておく。 その他に、データセットの読み込みなどに必要なパッケージもインストールしておく。
$ pip install prophet scikit-learn seaborn pmdarima
flights データセットで試してみる
まずは、航空機の旅客数を扱った有名な flights データセットで試してみる。
その前に、どういったデータかをグラフにプロットして確認しておく。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pandas as pd import seaborn as sns from matplotlib import pyplot as plt def main(): # flights データセットを読み込む df = sns.load_dataset('flights') # カラムが年と月で分かれているのでマージする df['year-month'] = pd.to_datetime(df['year'].astype(str) + '-' + df['month'].astype(str), format='%Y-%b') # プロットする plt.plot(df['year-month'], df['passengers']) plt.show() if __name__ == '__main__': main()
上記に適当な名前をつけて保存したら実行する。
$ python plotflights.py
すると、次のような折れ線グラフが得られる。
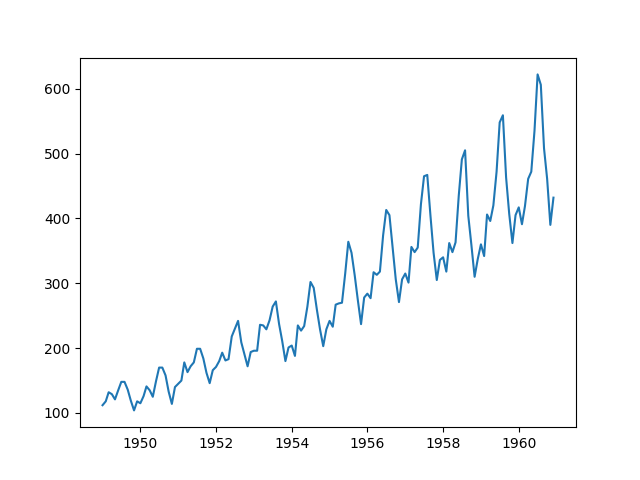
上記からトレンドや季節成分の存在が確認できる。
それでは、次に Prophet を使って予測してみよう。
以下のサンプルコードでは、データを時系列でホールドアウトして、末尾を Prophet で予測している。
Prophet のデフォルトでは、時系列のカラムを ds という名前で、目的変数のカラムを y という名前にすることになっている。
また、実際の値と予測をプロットしたものと、データをトレンドと季節成分に分離したものをグラフとしてプロットしている。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pandas as pd import seaborn as sns from matplotlib import pyplot as plt from sklearn.metrics import mean_absolute_error from sklearn.model_selection import train_test_split from prophet import Prophet def main(): # flights データセットを読み込む df = sns.load_dataset('flights') # カラムが年と月で分かれているのでマージする df['year-month'] = pd.to_datetime(df['year'].astype(str) + '-' + df['month'].astype(str), format='%Y-%b') # Prophet が仮定するカラム名に変更する # タイムスタンプ: ds # 目的変数: y rename_mappings = { 'year-month': 'ds', 'passengers': 'y', } df.rename(columns=rename_mappings, inplace=True) # 不要なカラムを落とす df.drop(['year', 'month'], axis=1, inplace=True) # 時系列の順序で学習・検証用データをホールアウトする train_df, eval_df = train_test_split(df, shuffle=False, random_state=42, test_size=0.3) # 学習用データを使って学習する m = Prophet() m.fit(train_df) # 検証用データを予測する forecast = m.predict(eval_df.drop(['y'], axis=1)) # 真の値との誤差を MAE で求める mae = mean_absolute_error(forecast['yhat'], eval_df['y']) print(f'MAE: {mae:.05f}') # 実際のデータと予測をプロットする fig = plt.figure(figsize=(12, 8)) ax = fig.add_subplot(1, 1, 1) ax.plot(df['ds'], df['y'], color='y') m.plot(forecast, ax=ax) # トレンドと季節成分をプロットする m.plot_components(forecast) plt.show() if __name__ == '__main__': main()
上記を実行してみよう。 実際の値と予測値の、ホールドアウトデータでの乖離を MAE で出力している。
$ python predflights.py ... MAE: 35.21388
実際の値と予測をプロットしたグラフは次のとおり。 青い実線が予測値、薄い青色で示された範囲は 95% 信頼区間らしい。
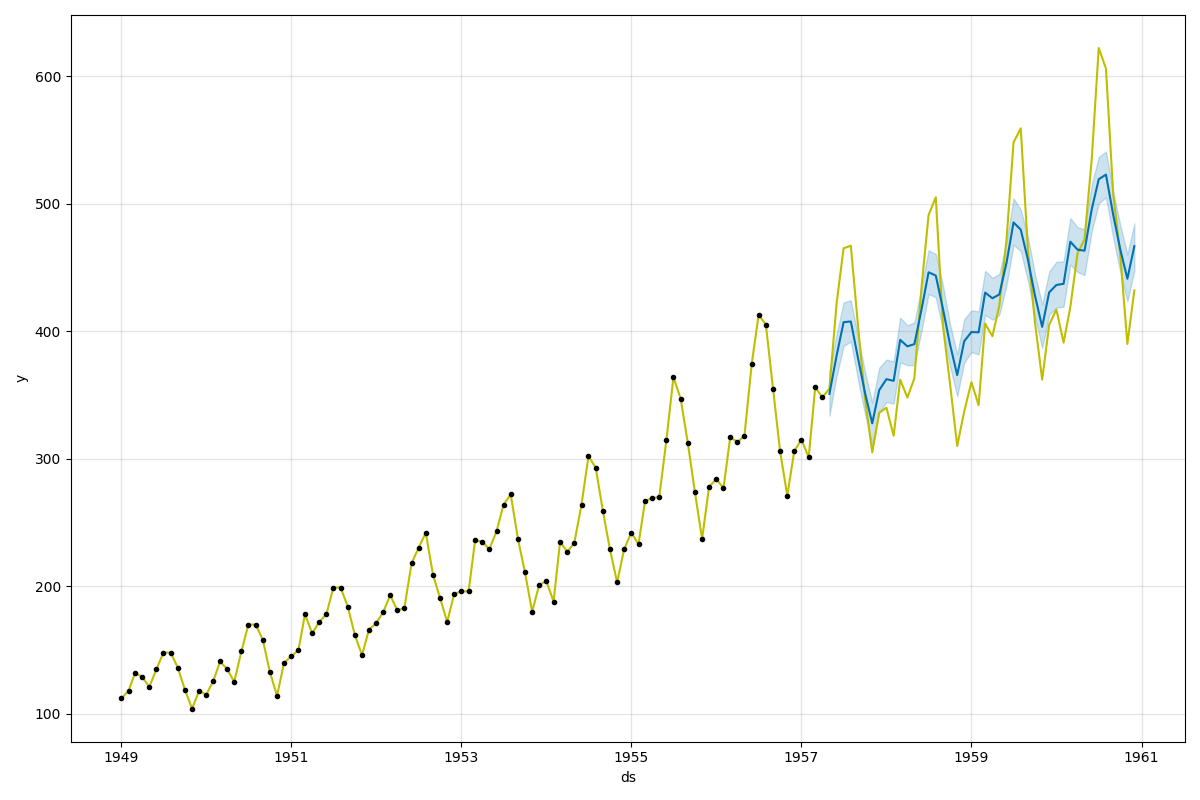
トレンドはつかめているものの、実際の値よりも振幅は小さくなっていることがわかる。
トレンドと季節成分は次のように分離された。 Prophet は特に指定しない限り、季節成分を自動で検出してくれる。 以下では年次でのトレンドが自動的に検出されたことが確認できる。
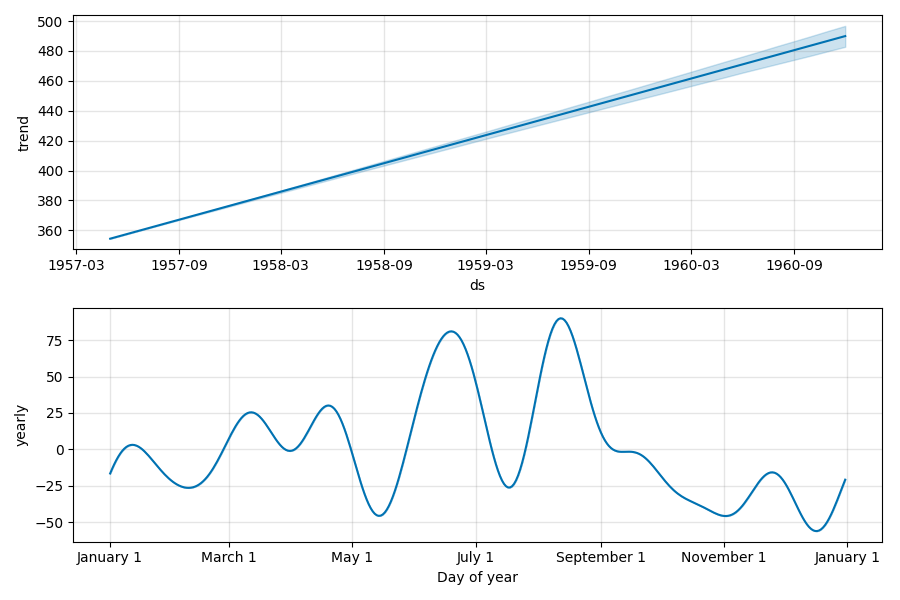
先ほどのモデルでは、振幅が小さいことで実際の値とのズレが大きくなってしまっていた。 これは、季節成分の計算がデフォルトで加算モードになっていたことが理由として考えられる。 つまり、時間が進むごとに目的変数が大きくなると共に振幅も大きくなることが上手く表現できていなかった。 そこで、次は季節成分の計算を乗法モードに変更してみる。 トレンド成分にかけ算で季節成分をのせてやれば、振幅がだんだんと大きくなっていく様子が表現できるはず。
以下のサンプルコードではモデルに seasonality_mode='multiplicative' を指定することで季節成分の計算を乗法モードにしている。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pandas as pd import seaborn as sns from matplotlib import pyplot as plt from sklearn.metrics import mean_absolute_error from sklearn.model_selection import train_test_split from prophet import Prophet def main(): df = sns.load_dataset('flights') df['year-month'] = pd.to_datetime(df['year'].astype(str) + '-' + df['month'].astype(str), format='%Y-%b') rename_mappings = { 'year-month': 'ds', 'passengers': 'y', } df.rename(columns=rename_mappings, inplace=True) df.drop(['year', 'month'], axis=1, inplace=True) train_df, eval_df = train_test_split(df, shuffle=False, random_state=42, test_size=0.3) # 季節成分の計算を加算モードから乗法モードに変更する m = Prophet(seasonality_mode='multiplicative') m.fit(train_df) forecast = m.predict(eval_df.drop(['y'], axis=1)) mae = mean_absolute_error(forecast['yhat'], eval_df['y']) print(f'MAE: {mae:.05f}') fig = plt.figure(figsize=(12, 8)) ax = fig.add_subplot(1, 1, 1) ax.plot(df['ds'], df['y'], color='y') m.plot(forecast, ax=ax) m.plot_components(forecast) plt.show() if __name__ == '__main__': main()
上記を実行してみよう。 かなり MAE が改善したことが確認できる。
$ python multiflights.py ... MAE: 22.31301
実際の値と予測値をグラフで確認しても、次のように当てはまりが良くなっている。
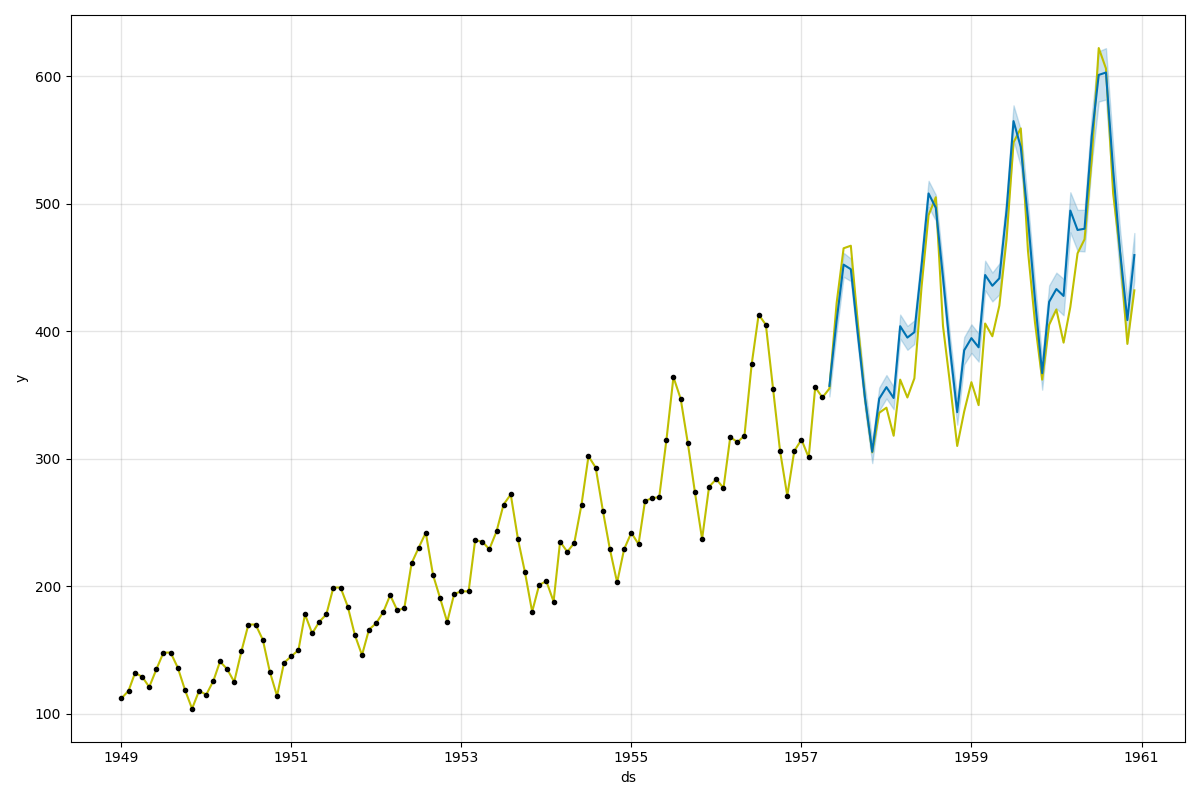
wineind データセットで試してみる
もうひとつ、ワインの生産量を示すデータセット (wineind) で試してみよう。
先ほどと同じように、まずはデータセットを可視化する。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pandas as pd from pmdarima import datasets from matplotlib import pyplot as plt def main(): # wineind データセットを読み込む series = datasets.load_wineind(as_series=True) df = series.to_frame(name='bottles') # プロットする df.plot() plt.show() if __name__ == '__main__': main()
上記を実行する。
$ python plotwineind.py
得られるグラフは次のとおり。 季節成分は確認できるものの、単調な増加トレンドがあるわけではないようだ。
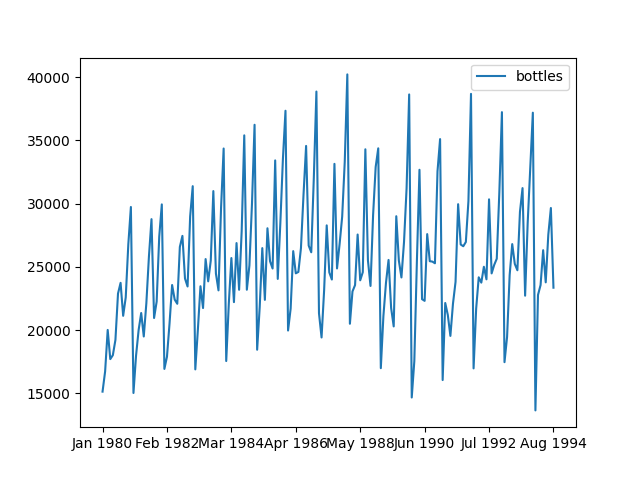
先ほどと同じように、データをホールドアウトして予測してみよう。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pandas as pd from pmdarima import datasets from matplotlib import pyplot as plt from sklearn.metrics import mean_absolute_error from sklearn.model_selection import train_test_split from prophet import Prophet def main(): series = datasets.load_wineind(as_series=True) df = series.to_frame(name='bottles') df.reset_index(inplace=True) df['index'] = pd.to_datetime(df['index'], format='%b %Y') rename_mappings = { 'index': 'ds', 'bottles': 'y', } df.rename(columns=rename_mappings, inplace=True) train_df, eval_df = train_test_split(df, shuffle=False, random_state=42, test_size=0.3) m = Prophet(seasonality_mode='multiplicative') m.fit(train_df) forecast = m.predict(eval_df.drop(['y'], axis=1)) mae = mean_absolute_error(forecast['yhat'], eval_df['y']) print(f'MAE: {mae:.05f}') fig = plt.figure(figsize=(12, 8)) ax = fig.add_subplot(1, 1, 1) ax.plot(df['ds'], df['y'], color='y') m.plot(forecast, ax=ax) m.plot_components(forecast) plt.show() if __name__ == '__main__': main()
上記を実行する。
$ python predwineind.py ... MAE: 2443.18595
得られた予測は次のとおり。 今回は、先ほどよりも実際の値と予測が一致していない。 中には実際の値が 95% 信頼区間の外に出てしまっているものもある。
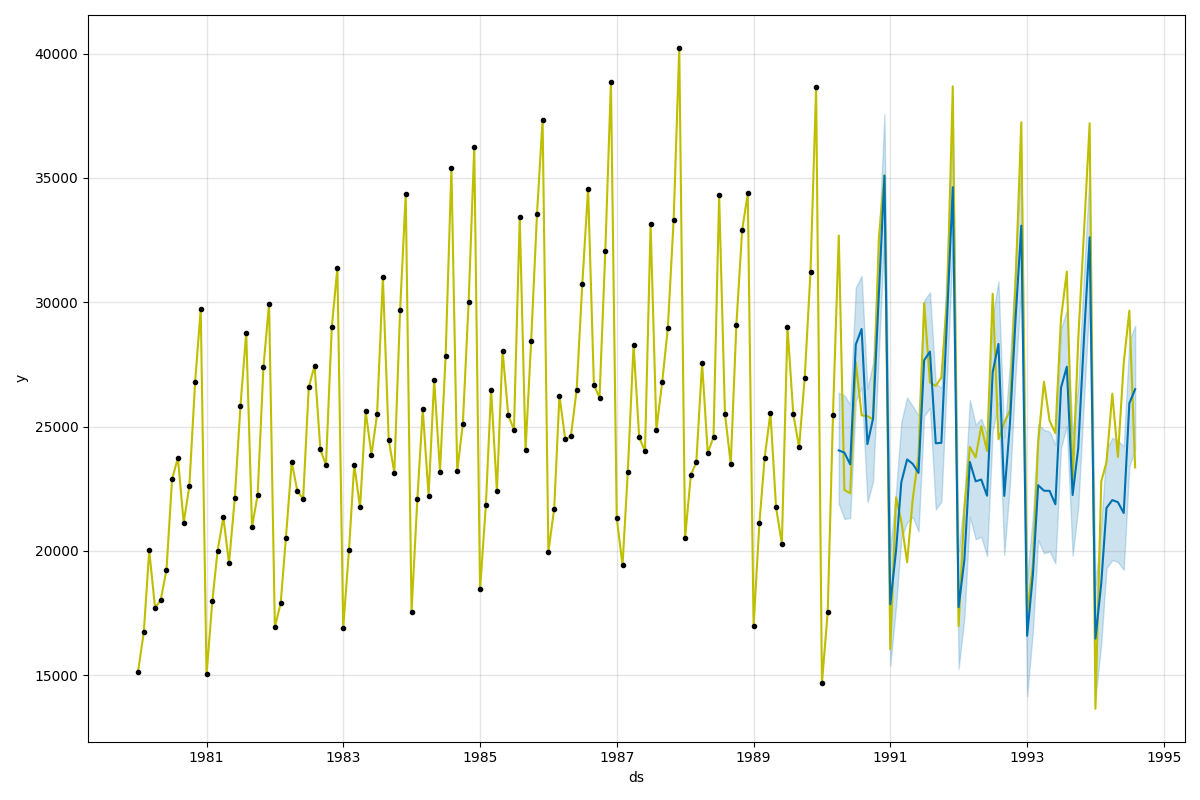
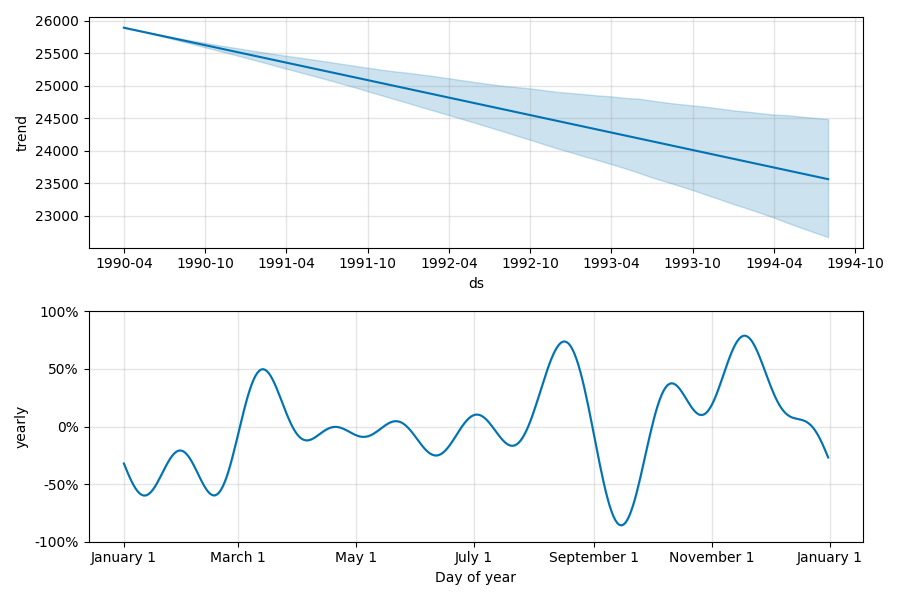
トレンドと季節成分は次のとおり。 今度は単調な下降トレンドと認識されているようだ。 もちろん、これらの結果は学習させる範囲にも大きく依存する。
まとめ
今回は Prophet を使って時系列の予測を試してみた。 ごくシンプルな時系列データで、なるべく簡単にトレンドや季節成分を加味した予測をしたいときには選択肢の一つとして考えられるかもしれない。
")
