>>> data = {
... "group": ["A", "A", "A", "B", "B", "C"],
... "value": [10, 20, 30, 40, 50, 60],
... }
>>> import pandas as pd
>>> df = pd.DataFrame(data)
>>> df
group value
0 A 101 A 202 A 303 B 404 B 505 C 60
上記から AggregationEncoder を使って集約特徴量を計算する準備をする。
まず、グルーピングのキーとして group_keys 引数にリストで group カラムを指定する。
同様に、バリューとして group_values 引数にリストで value カラムを指定する。
計算する統計量としては、agg_methods 引数で出現回数 (count) と平均 (mean) を指定した。
>>> import numpy as np
>>> data = {
... "group1": ["A", "A", "A", "B", "B", "C"],
... "group2": ["x", "y", "z", "x", "y", "z"],
... "value1": [10, 20, 30, 40, 50, 60],
... "value2": [np.nan, 500, 400, 300, 200, 100],
... }
>>> df = pd.DataFrame(data)
>>> df
group1 group2 value1 value2
0 A x 10 NaN
1 A y 20500.02 A z 30400.03 B x 40300.04 B y 50200.05 C z 60100.0
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.4 LTS
Release: 20.04
Codename: focal
$ uname -srm
Linux 5.4.0-109-generic aarch64
$ pivot_root --version
pivot_root from util-linux 2.34
$ gcc --version
gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1)9.4.0
Copyright (C)2019 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ ldd --version
ldd (Ubuntu GLIBC 2.31-0ubuntu9.7)2.31
Copyright (C)2020 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Written by Roland McGrath and Ulrich Drepper.
$ sudo ip netns add ht1
$ sudo ip netns add sw1
$ sudo ip netns add rt1
$ sudo ip netns add rt2
$ sudo ip netns add sw2
$ sudo ip netns add ht2
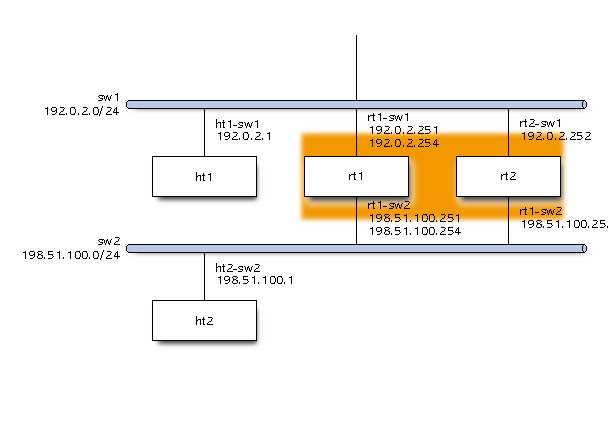
続いて、veth インターフェイスのペアを作成する。
こちらも、名前は論理構成図と対応する。
$ sudo ip link add ht1-veth0 type veth peer name ht1-sw1
$ sudo ip link add ht2-veth0 type veth peer name ht2-sw2
$ sudo ip link add rt1-veth0 type veth peer name rt1-sw1
$ sudo ip link add rt1-veth1 type veth peer name rt1-sw2
$ sudo ip link add rt2-veth0 type veth peer name rt2-sw1
$ sudo ip link add rt2-veth1 type veth peer name rt2-sw2
作成したネットワークインターフェイスを Network Namespace に所属させていく。
$ sudo ip link set ht1-veth0 netns ht1
$ sudo ip link set ht2-veth0 netns ht2
$ sudo ip link set ht1-sw1 netns sw1
$ sudo ip link set ht2-sw2 netns sw2
$ sudo ip link set rt1-veth0 netns rt1
$ sudo ip link set rt1-veth1 netns rt1
$ sudo ip link set rt1-sw1 netns sw1
$ sudo ip link set rt1-sw2 netns sw2
$ sudo ip link set rt2-veth0 netns rt2
$ sudo ip link set rt2-veth1 netns rt2
$ sudo ip link set rt2-sw1 netns sw1
$ sudo ip link set rt2-sw2 netns sw2
Network Namespace に所属させたインターフェイスの状態を UP にする。
$ sudo ip netns exec ht1 ip link set ht1-veth0 up
$ sudo ip netns exec ht2 ip link set ht2-veth0 up
$ sudo ip netns exec sw1 ip link set ht1-sw1 up
$ sudo ip netns exec sw2 ip link set ht2-sw2 up
$ sudo ip netns exec rt1 ip link set rt1-veth0 up
$ sudo ip netns exec rt1 ip link set rt1-veth1 up
$ sudo ip netns exec sw1 ip link set rt1-sw1 up
$ sudo ip netns exec sw2 ip link set rt1-sw2 up
$ sudo ip netns exec rt2 ip link set rt2-veth0 up
$ sudo ip netns exec rt2 ip link set rt2-veth1 up
$ sudo ip netns exec sw1 ip link set rt2-sw1 up
$ sudo ip netns exec sw2 ip link set rt2-sw2 up
今回は 3 つ以上のネットワークインターフェイスが同じネットワークセグメントに所属するため、ブリッジが必要になる。
Linux Bridge として用意する。
$ sudo ip netns exec sw1 ip link add dev sw1-br0 type bridge
$ sudo ip netns exec sw1 ip link set sw1-br0 up
$ sudo ip netns exec sw2 ip link add dev sw2-br0 type bridge
$ sudo ip netns exec sw2 ip link set sw2-br0 up
ブリッジにネットワークインターフェイスを接続する。
$ sudo ip netns exec sw1 ip link set ht1-sw1 master sw1-br0
$ sudo ip netns exec sw1 ip link set rt1-sw1 master sw1-br0
$ sudo ip netns exec sw1 ip link set rt2-sw1 master sw1-br0
$ sudo ip netns exec sw2 ip link set ht2-sw2 master sw2-br0
$ sudo ip netns exec sw2 ip link set rt1-sw2 master sw2-br0
$ sudo ip netns exec sw2 ip link set rt2-sw2 master sw2-br0
インターフェイスに IP アドレスを付与する。
$ sudo ip netns exec ht1 ip address add 192.0.2.1/24 dev ht1-veth0
$ sudo ip netns exec ht2 ip address add 198.51.100.1/24 dev ht2-veth0
$ sudo ip netns exec rt1 ip address add 192.0.2.251/24 dev rt1-veth0
$ sudo ip netns exec rt1 ip address add 198.51.100.251/24 dev rt1-veth1
$ sudo ip netns exec rt2 ip address add 192.0.2.252/24 dev rt2-veth0
$ sudo ip netns exec rt2 ip address add 198.51.100.252/24 dev rt2-veth1
ルータとして動作するようにカーネルのパラメータを設定する。
$ sudo ip netns exec rt1 sysctl net.ipv4.ip_forward=1
$ sudo ip netns exec rt2 sysctl net.ipv4.ip_forward=1
$ sudo ip netns exec ht1 ip route add default via 192.0.2.254
$ sudo ip netns exec ht2 ip route add default via 198.51.100.254
下準備が終わったので、まずはセグメントに閉じた疎通を確認しておく。
$ sudo ip netns exec ht1 ping -c3192.0.2.251
PING 192.0.2.251(192.0.2.251)56(84) bytes of data.
64 bytes from 192.0.2.251: icmp_seq=1ttl=64time=0.141 ms
64 bytes from 192.0.2.251: icmp_seq=2ttl=64time=0.181 ms
64 bytes from 192.0.2.251: icmp_seq=3ttl=64time=0.179 ms
--- 192.0.2.251 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2072ms
rtt min/avg/max/mdev =0.141/0.167/0.181/0.018 ms
$ sudo ip netns exec ht1 ping -c3192.0.2.252
PING 192.0.2.252(192.0.2.252)56(84) bytes of data.
64 bytes from 192.0.2.252: icmp_seq=1ttl=64time=0.132 ms
64 bytes from 192.0.2.252: icmp_seq=2ttl=64time=0.151 ms
64 bytes from 192.0.2.252: icmp_seq=3ttl=64time=0.098 ms
--- 192.0.2.252 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2098ms
rtt min/avg/max/mdev =0.098/0.127/0.151/0.021 ms
$ sudo ip netns exec ht2 ping -c3198.51.100.251
PING 198.51.100.251(198.51.100.251)56(84) bytes of data.
64 bytes from 198.51.100.251: icmp_seq=1ttl=64time=0.113 ms
64 bytes from 198.51.100.251: icmp_seq=2ttl=64time=0.174 ms
64 bytes from 198.51.100.251: icmp_seq=3ttl=64time=0.163 ms
--- 198.51.100.251 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2071ms
rtt min/avg/max/mdev =0.113/0.150/0.174/0.026 ms
$ sudo ip netns exec ht2 ping -c3198.51.100.252
PING 198.51.100.252(198.51.100.252)56(84) bytes of data.
64 bytes from 198.51.100.252: icmp_seq=1ttl=64time=0.132 ms
64 bytes from 198.51.100.252: icmp_seq=2ttl=64time=0.162 ms
64 bytes from 198.51.100.252: icmp_seq=3ttl=64time=0.167 ms
--- 198.51.100.252 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2088ms
rtt min/avg/max/mdev =0.132/0.153/0.167/0.015 ms
$ sudo keepalived -nlP-p /var/run/keepalived1 -f rt1-keepalived.conf
Sun Apr 3 00:07:54 2022: Starting Keepalived v2.0.19(10/19,2019)
Sun Apr 3 00:07:54 2022: WARNING - keepalived was build for newer Linux 5.4.166, running on Linux 5.4.0-107-generic #121-Ubuntu SMP Thu Mar 24 16:07:22 UTC 2022
Sun Apr 3 00:07:54 2022: Command line: 'keepalived''-nlP''-p''/var/run/keepalived1''-f''rt1-keepalived.conf'
Sun Apr 3 00:07:54 2022: Opening file 'rt1-keepalived.conf'.
Sun Apr 3 00:07:54 2022: Changing syslog ident to Keepalived_rt1
Sun Apr 3 00:07:54 2022: Starting VRRP child process, pid=1897
Sun Apr 3 00:07:54 2022: Registering Kernel netlink reflector
Sun Apr 3 00:07:54 2022: Registering Kernel netlink command channel
Sun Apr 3 00:07:54 2022: Opening file 'rt1-keepalived.conf'.
Sun Apr 3 00:07:54 2022: Registering gratuitous ARP shared channel
Sun Apr 3 00:07:54 2022: (VirtualInstance1) Entering BACKUP STATE (init)
Sun Apr 3 00:07:54 2022: (VirtualInstance2) Entering BACKUP STATE (init)
Sun Apr 3 00:07:57 2022: (VirtualInstance1) Entering MASTER STATE
Sun Apr 3 00:07:57 2022: VRRP_Group(VirtualGroup1) Syncing instances to MASTER state
Sun Apr 3 00:07:57 2022: (VirtualInstance2) Entering MASTER STATE
Entering MASTER STATE という表示が出れば、ルータがマスターになったことを表している。
別のターミナルを開いて rt1 の IP アドレスを確認すると、ちゃんと VIP が付与されている。
$ sudo ip netns exec rt1 ip address show | grep .254/24
inet 192.0.2.254/24 scope global secondary rt1-veth0
inet 198.51.100.254/24 scope global secondary rt1-veth1
$ sudo ip netns exec ht1 ping -c3198.51.100.1
PING 198.51.100.1(198.51.100.1)56(84) bytes of data.
64 bytes from 198.51.100.1: icmp_seq=1ttl=63time=0.166 ms
64 bytes from 198.51.100.1: icmp_seq=2ttl=63time=0.192 ms
64 bytes from 198.51.100.1: icmp_seq=3ttl=63time=0.214 ms
--- 198.51.100.1 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2087ms
rtt min/avg/max/mdev =0.166/0.190/0.214/0.019 ms
$ sudo keepalived -nlP-p /var/run/keepalived1 -f rt1-keepalived.conf
...(省略)...
Sun Apr 3 00:48:37 2022: Netlink reports rt1-veth0 down
Sun Apr 3 00:48:37 2022: (VirtualInstance1) Entering FAULT STATE
Sun Apr 3 00:48:37 2022: (VirtualInstance1) sent 0 priority
Sun Apr 3 00:48:37 2022: VRRP_Group(VirtualGroup1) Syncing instances to FAULT state
Sun Apr 3 00:48:37 2022: (VirtualInstance2) Entering FAULT STATE
代わりに rt2 の方がマスターに昇格した。
$ sudo keepalived -nlP-p /var/run/keepalived2 -f rt2-keepalived.conf
...(省略)...
Sun Apr 3 00:48:37 2022: (VirtualInstance2) Backup received priority 0 advertisement
Sun Apr 3 00:48:39 2022: (VirtualInstance1) Entering MASTER STATE
Sun Apr 3 00:48:39 2022: VRRP_Group(VirtualGroup1) Syncing instances to MASTER state
Sun Apr 3 00:48:39 2022: (VirtualInstance2) Entering MASTER STATE
VIP を確認しても rt2 の方に移動している。
$ sudo ip netns exec rt1 ip address show | grep .254/24
$ sudo ip netns exec rt2 ip address show | grep .254/24
inet 192.0.2.254/24 scope global secondary rt2-veth0
inet 198.51.100.254/24 scope global secondary rt2-veth1
$ sudo ip netns exec rt2 ip address show | grep .254/24
inet 192.0.2.254/24 scope global secondary rt2-veth0
inet 198.51.100.254/24 scope global secondary rt2-veth1
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.4 LTS
Release: 20.04
Codename: focal
$ uname -srm
Linux 5.4.0-104-generic aarch64
$ chroot --version
chroot (GNU coreutils)8.30
Copyright (C)2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <https://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Written by Roland McGrath.
$ gcc --version
gcc (Ubuntu 9.4.0-1ubuntu1~20.04)9.4.0
Copyright (C)2019 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ ldd --version
ldd (Ubuntu GLIBC 2.31-0ubuntu9.7)2.31
Copyright (C)2020 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Written by Roland McGrath and Ulrich Drepper.
# cat /etc/lsb-release DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=21.10DISTRIB_CODENAME=impish
DISTRIB_DESCRIPTION="Ubuntu 21.10"# bash --version
GNU bash, version 5.1.8(1)-release (aarch64-unknown-linux-gnu)
Copyright (C)2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
# ls /
bin boot dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
# cat /etc/lsb-release DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=21.10DISTRIB_CODENAME=impish
DISTRIB_DESCRIPTION="Ubuntu 21.10"

")