Streamlit は、ざっくり言うと主にデータサイエンス領域において WebUI 付きのアプリケーションを手早く作るためのソフトウェア。
使い所としては、ひとまず動くものを見せたかったり、少人数で試しに使うレベルのプロトタイプを作るフェーズに適していると思う。
たとえば、Jupyter で提供すると複数人で使うのに難があるし、かといって Flask や Django を使って真面目に作るほどではない、くらいのとき。
使った環境は次のとおり。
$ sw_vers
ProductName: macOS
ProductVersion: 11.3.1
BuildVersion: 20E241
$ python -V
Python 3.8.9
もくじ
下準備
まずは必要なパッケージをインストールしておく。
本当に必要なのは streamlit のみ。
watchdog はパフォーマンスのために入れる。
matplotlib についてはグラフを可視化するときに使うため入れておく。
click はスクリプトに引数を渡すサンプルのため。
$ pip install streamlit watchdog matplotlib click
インストールすると streamlit コマンドが使えるようになる。
$ streamlit version
Streamlit, version 0.81.0
必要に応じて Streamlit の設定ファイルを用意する。
以下は、初回の実行時に確認される e-mail アドレスのスキップと、利用に関する統計情報を送信しない場合の設定。
なお、これは別にやらなくても初回の実行時に案内が出る。
$ mkdir -p ~/.streamlit
$ cat << 'EOF' > ~/.streamlit/credentials.toml
[general]
email = ""
EOF
$ cat << 'EOF' > ~/.streamlit/config.toml
[browser]
gatherUsageStats = false
EOF
基本的な使い方
まずはもっとも基本的な使い方から見ていく。
以下は streamlit.write() 関数を使って任意のオブジェクトを WebUI に表示するサンプルコード。
import streamlit as st
def main():
st.write('Hello, World!')
if __name__ == '__main__':
main()
上記を適当な名前で保存したら streamlit run サブコマンドで指定して実行する。
$ streamlit run example.py
すると、デフォルトでは 8501 ポートで Streamlit のアプリケーションサーバが起動する。
ブラウザで開いて結果を確認しよう。
$ open http://localhost:8501
すると、次のように「Hello, World!」という表示のある Web ページが確認できる。
やっていることは静的な文字列を表示しているだけとはいえ、Pure Python なスクリプトをちょっと書くだけで Web ページが表示できた。
なお、Streamlit はデフォルトだと実行するホストの全 IP アドレスを Listen するので注意しよう。
ループバックアドレスだけに絞りたいときは以下のようにする。
$ streamlit run --server.address localhost example.py
ちなみに先ほど使った streamlit.write() 関数は色々なオブジェクトを可視化するのに使うことができる。
現時点で対応しているものをざっと書き出してみると次のとおり。
- サードパーティー製パッケージ関連
- Pandas の DataFrame オブジェクト
- Keras の Model オブジェクト
- SymPy の表現式 (LaTeX)
- グラフ描画系
- Matplotlib
- Altair
- Vega Lite
- Plotly
- Bokeh
- PyDeck
- Graphviz
- 標準的な Python のオブジェクト
- 例外オブジェクト
- 関数オブジェクト
- モジュールオブジェクト
- 辞書オブジェクト
その他、任意のオブジェクトは str() 関数に渡したのと等価な結果が得られる。
基本的な書式
続いて、Streamlit に備わっている基本的な書式をいくつか試してみる。
アプリケーションのタイトルやヘッダ、マークダウンテキストや数式など。
import streamlit as st
def main():
st.title('Application title')
st.header('Header')
st.text('Some text')
st.subheader('Sub header')
st.markdown('**Markdown is available **')
st.latex(r'\bar{X} = \frac{1}{N} \sum_{n=1}^{N} x_i')
st.code('print(\'Hello, World!\')')
st.error('Error message')
st.warning('Warning message')
st.info('Information message')
st.success('Success message')
st.exception(Exception('Oops!'))
d = {
'foo': 'bar',
'users': [
'alice',
'bob',
],
}
st.json(d)
if __name__ == '__main__':
main()
先ほどの Python ファイルに上書きすると、Streamlit はファイルの変更を検知して自動的に読み込み直してくれる。
アプリケーションを表示しているブラウザはリロードするか、変更が生じた際に自動で読み込むか問うボタンが右上に出てくる。

プレースホルダー
続いて扱うのはプレースホルダーという機能。
かなり地味なので、この時点で紹介する点に違和感があるかもしれない。
とはいえ、地味なりに多用する機能なので先に説明しておく。
プレースホルダーは、任意のオブジェクトを表示するための入れ物みたいなオブジェクト。
言葉よりも実際に使った方が分かりやすいと思うので以下にサンプルを示す。
プレースホルダーを用意して、後からそこにオブジェクトを書き込む、みたいな使い方をする。
import streamlit as st
def main():
placeholder1 = st.empty()
placeholder1.write('Hello, World')
placeholder2 = st.empty()
with placeholder2:
st.write(1)
st.write(2)
st.write(3)
if __name__ == '__main__':
main()
上記を実行した結果は次のとおり。
プレースホルダーの内容は上書きされるので、特に何もしなければ最後に書きこまれた内容が見える。

プレースホルダーを応用するとアニメーション的なこともできる。
以下のサンプルコードではスリープを挟みながらプレースホルダーの内容を書きかえることで動きのあるページを作っている。
import time
import streamlit as st
def main():
status_area = st.empty()
count_down_sec = 5
for i in range(count_down_sec):
status_area.write(f'{count_down_sec - i} sec left')
time.sleep(1)
status_area.write('Done!')
st.balloons()
if __name__ == '__main__':
main()
上記を実行すると秒数のカウントダウンが確認できる。
プログレスバーを使った処理の進捗の可視化
ちなみに先ほどのようなカウントダウンをするような処理だとプログレスバーを使うこともできる。
以下のサンプルコードでは 0.1 秒ごとにプログレスバーの数値を増やしていくページができる。
import time
import streamlit as st
def main():
status_text = st.empty()
progress_bar = st.progress(0)
for i in range(100):
status_text.text(f'Progress: {i}%')
progress_bar.progress(i + 1)
time.sleep(0.1)
status_text.text('Done!')
st.balloons()
if __name__ == '__main__':
main()
上記を実行すると、以下のようにプログレスバーが表示される。
基本的な可視化
ここまでの内容だと、面白いけど何が便利なのかイマイチよく分からないと思う。
そこで、ここからはもう少し実用的な話に入っていく。
具体的には、いくつかグラフなどを可視化する方法について見ていこう。
組み込みのグラフ描画機能
Streamlit には組み込みのグラフ描画機能がある。
この機能を使うと NumPy の配列や Pandas のデータフレームなどをサクッとグラフにできる。
以下のサンプルコードでは折れ線グラフ、エリアチャート、バーチャートの 3 種類を試している。
import streamlit as st
import pandas as pd
import numpy as np
def main():
data = {
'x': np.random.random(20),
'y': np.random.random(20) - 0.5,
'z': np.random.random(20) - 1.0,
}
df = pd.DataFrame(data)
st.subheader('Line Chart')
st.line_chart(df)
st.subheader('Area Chart')
st.area_chart(df)
st.subheader('Bar Chart')
st.bar_chart(df)
if __name__ == '__main__':
main()
上記からは次のようなグラフが得られる。
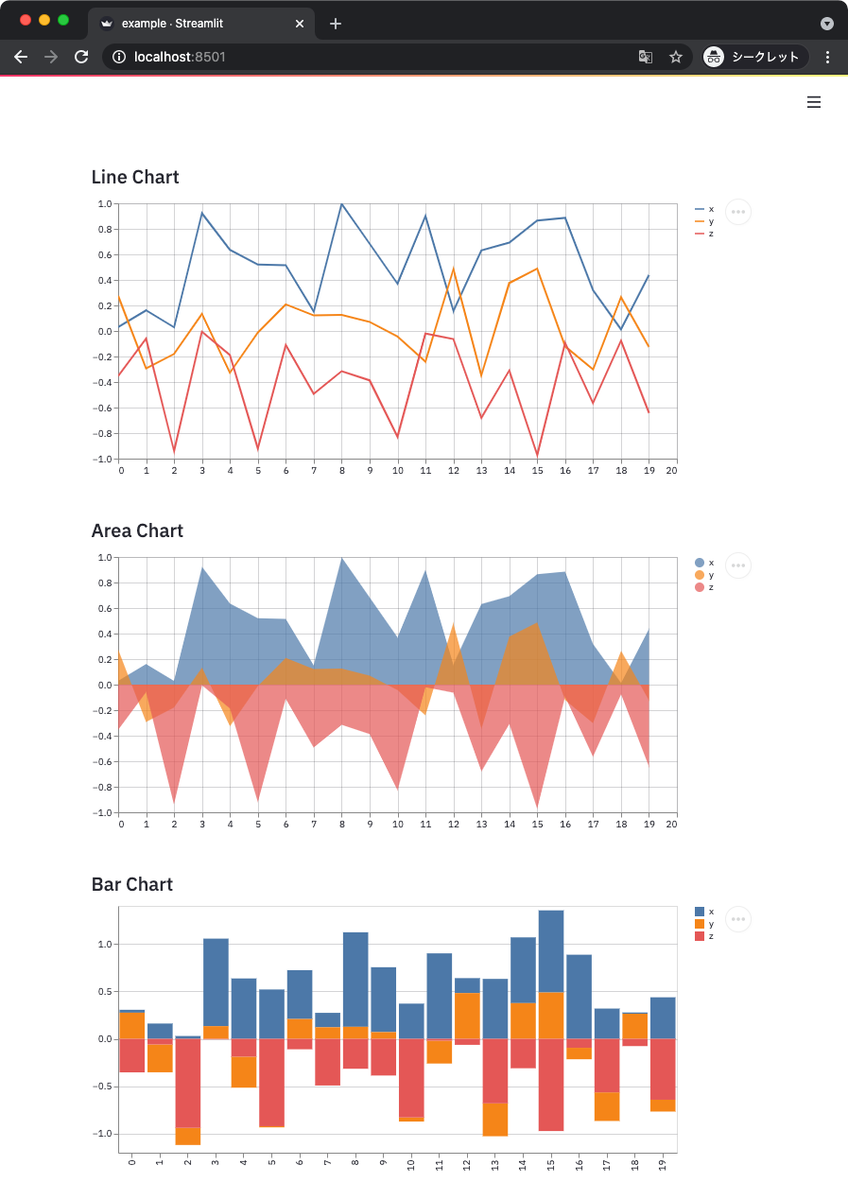
グラフにデータを動的に追加することもできる。
これにはグラフを描画する関数を実行して得られるオブジェクトに add_rows() メソッドを使えば良い。
以下のサンプルコードでは、折れ線グラフに 0.5 秒間隔で 10 回までデータを追加している。
import time
import streamlit as st
import numpy as np
def main():
x = np.random.random(size=(10, 2))
line_chart = st.line_chart(x)
for i in range(10):
additional_data = np.random.random(size=(5, 2))
line_chart.add_rows(additional_data)
time.sleep(0.5)
if __name__ == '__main__':
main()
上記を確認すると、0.5 秒間隔でグラフにデータが追加されていく様子が確認できる。
こういったアニメーション効果を手軽に導入できるのは Streamlit の強みだと思う。
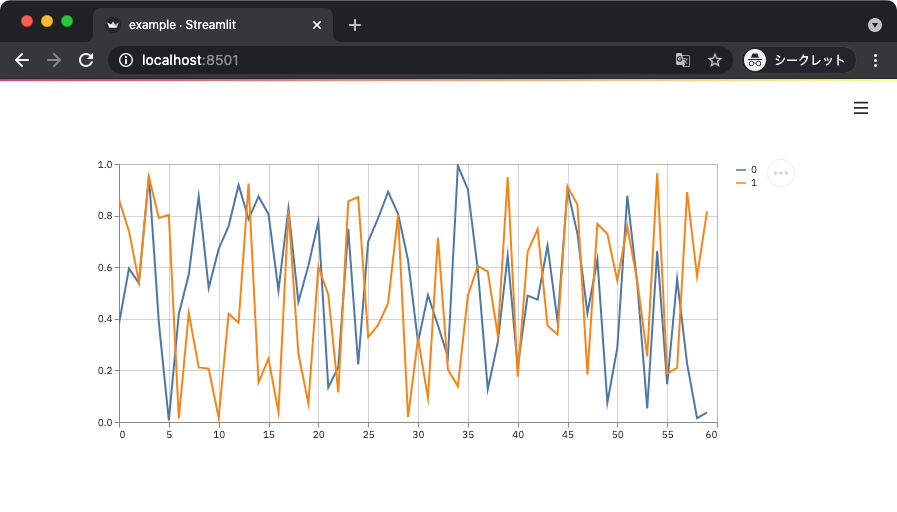
ちなみに気づいたかもしれないけどブラウザをリロードするごとにプロットされる結果は変わる。
これは Streamlit がページを表示するときに、スクリプトを上から順に実行するように処理しているため。
つまり、ブラウザをリロードする毎にスクリプトのコードが評価され直しているように考えれば良い。
Matplotlib
続いては Matplotlib のグラフを描画してみよう。
Streamlit では Matplotlib の Figure オブジェクトを書き出すことでグラフを描画できる。
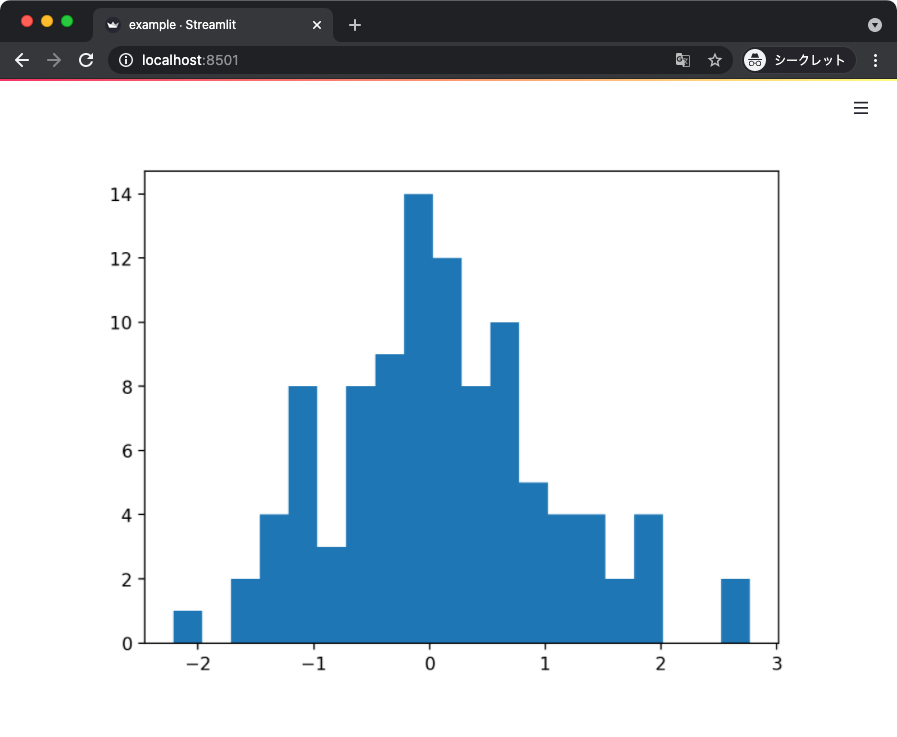
以下のサンプルコードではランダムに生成した値をヒストグラムにプロットしている。
import streamlit as st
import numpy as np
from matplotlib import pyplot as plt
def main():
fig = plt.figure()
ax = fig.add_subplot()
x = np.random.normal(loc=.0, scale=1., size=(100,))
ax.hist(x, bins=20)
st.pyplot(fig)
if __name__ == '__main__':
main()
上記からは次のような画面が得られる。
先ほどと同じように、データを更新しながらグラフを描画し直すサンプルも書いてみる。
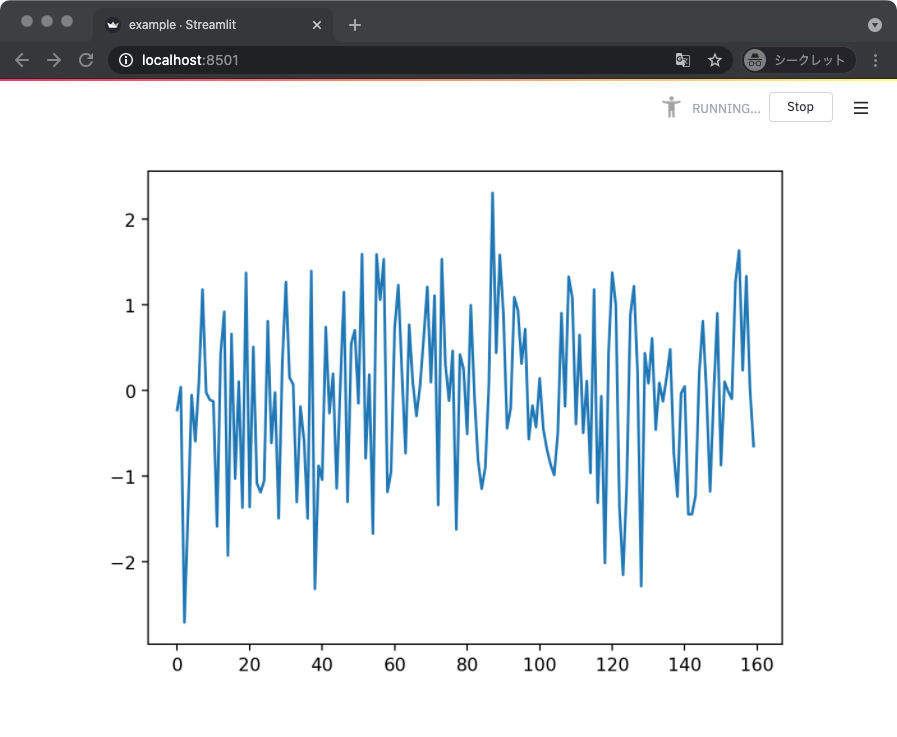
以下のサンプルコードでは、プレースホルダを使って描画されるグラフの内容を更新している。
import time
import streamlit as st
import numpy as np
from matplotlib import pyplot as plt
def main():
plot_area = st.empty()
fig = plt.figure()
ax = fig.add_subplot()
x = np.random.normal(loc=.0, scale=1., size=(100,))
ax.plot(x)
plot_area.pyplot(fig)
for i in range(10):
ax.clear()
additional_data = np.random.normal(loc=.0, scale=1., size=(10,))
x = np.concatenate([x, additional_data])
ax.plot(x)
plot_area.pyplot(fig)
time.sleep(0.5)
if __name__ == '__main__':
main()
上記を実行すると、一定間隔でデータが追加されながらグラフの描画も更新される。
Pandas
グラフではないけど Pandas のデータフレームを Jupyter で可視化するときと同じように表示できる。
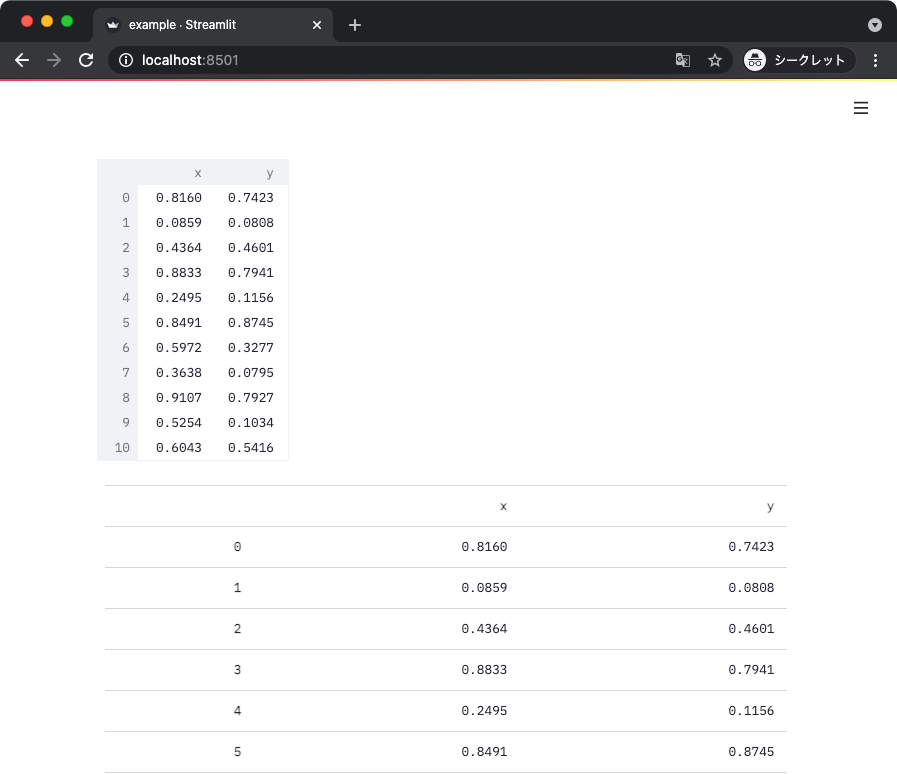
データフレームを出力するときは streamlit.dataframe() と streamlit.table() という 2 種類の関数がある。
前者は行や列の要素が多いときにスクロールバーを使って表示する一方で、後者はすべてをいっぺんに表示する。
import streamlit as st
import pandas as pd
import numpy as np
def main():
data = {
'x': np.random.random(20),
'y': np.random.random(20),
}
df = pd.DataFrame(data)
st.dataframe(df)
st.table(df)
if __name__ == '__main__':
main()
上記からは以下のような表示が得られる。
画像
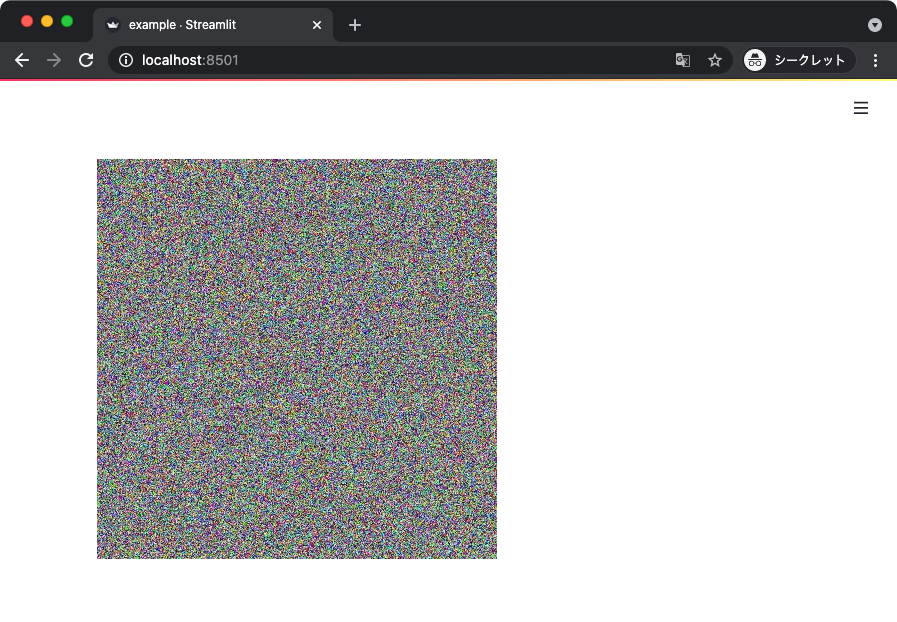
画像を表示するときは streamlit.image() 関数を使う。
以下のサンプルコードではランダムに生成した NumPy 配列を、カラー画像として可視化している。
import streamlit as st
import numpy as np
def main():
x = np.random.random(size=(400, 400, 3))
st.image(x)
if __name__ == '__main__':
main()
上記からは以下のような表示が得られる。
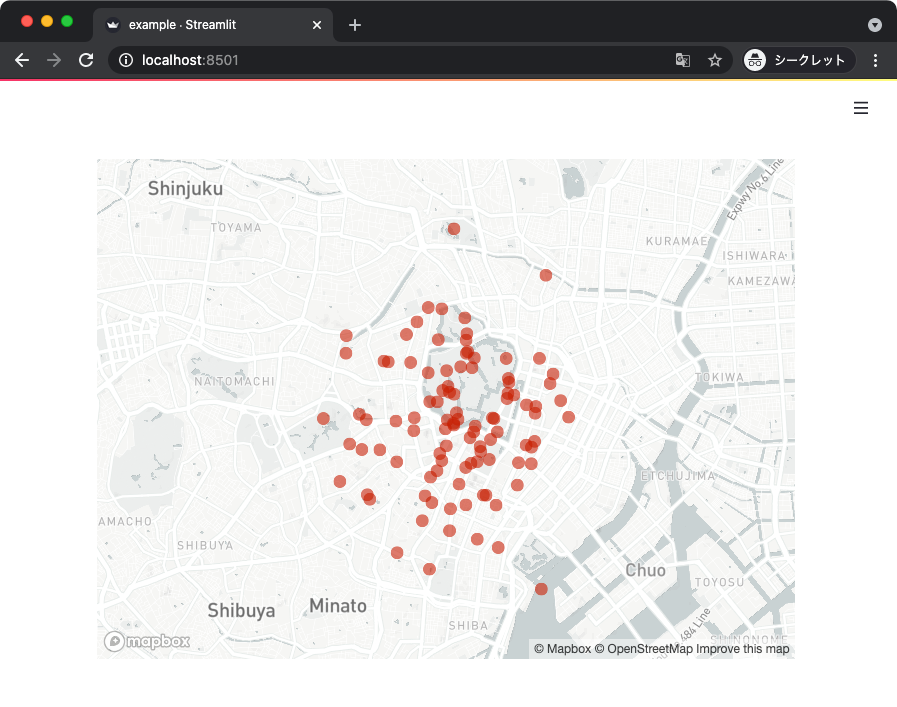
地図
地図上にプロットすることもできる。
地図に散布図を描きたいときは streamlit.map() 関数を使えば良い。
以下のサンプルコードでは、東京を中心とした地図にランダムな点をプロットしている。
import streamlit as st
import pandas as pd
import numpy as np
def main():
data = {
'lat': np.random.randn(100) / 100 + 35.68,
'lon': np.random.randn(100) / 100 + 139.75,
}
map_data = pd.DataFrame(data)
st.map(map_data)
if __name__ == '__main__':
main()
上記からは以下のような表示が得られる。
Streamlit がサポートしている可視化の機能は他にも色々とあるけど、とりあえず一旦はここまでで切り上げる。
キャッシュ機構
ここまでのサンプルコードは、ブラウザをリロードすると表示される内容が変わるものが多かった。
それはスクリプトの内容が毎回、評価し直されているのと同じ状態のため。
ただ、それだと困る場面も多い。
たとえば、時間のかかる処理が毎回評価され直すと、パフォーマンスに深刻な影響がある。
そんなときは Streamlit のキャッシュ機構を使うと良い。
キャッシュ機構を使うには streamlit.cache デコレータを使えば良い。
以下のサンプルコードでは、cached_data() 関数をデコレータで修飾している。
import streamlit as st
import pandas as pd
import numpy as np
@st.cache
def cached_data():
data = {
'x': np.random.random(20),
'y': np.random.random(20),
}
df = pd.DataFrame(data)
return df
def main():
df = cached_data()
st.dataframe(df)
if __name__ == '__main__':
main()
上記はオンメモリで結果がキャッシュされるため、ブラウザをリロードしても表示が変わることがない。
その他、キャッシュ機構の詳しい解説は以下のドキュメントに記載されている。
docs.streamlit.io
ウィジェット
ここまでのサンプルには、ユーザからの入力を受け付けるものがなかった。
ここからは、ウィジェットを使ってインタラクティブなページを作る方法について書く。
ボタン
まずは最も基本的なウィジェットとしてボタンを扱う。
このボタン、Streamlit のウィジェットの考え方が、他の UI フレームワークと違うことがよく分かって面白い。
ボタンは streamlit.button() 関数を使って配置できる。
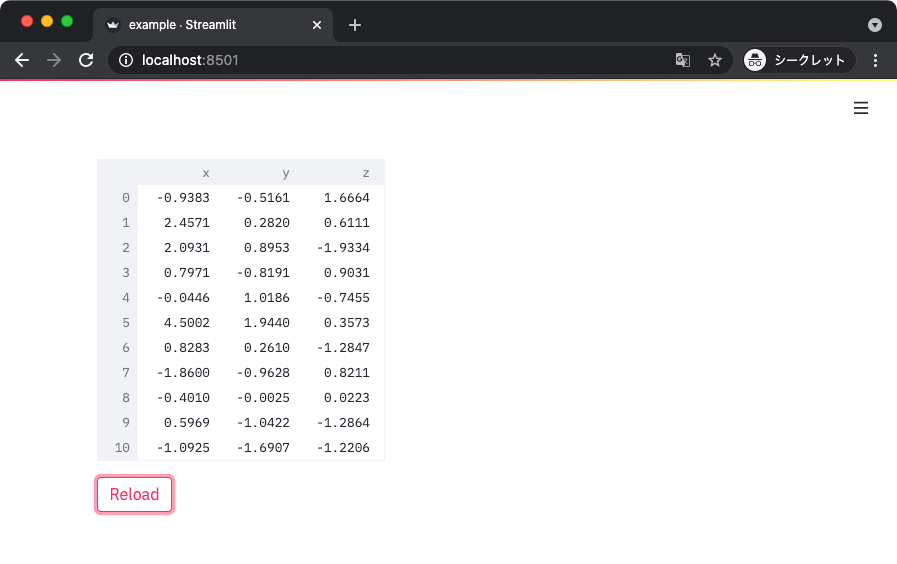
以下のサンプルコードは、ボタンを押すことで表示される内容が変わるものとなっている。
興味深いのは、ボタンにイベントハンドラなどの類が一切設定されていないこと。
import streamlit as st
import pandas as pd
import numpy as np
def main():
data = np.random.randn(20, 3)
df = pd.DataFrame(data, columns=['x', 'y', 'z'])
st.dataframe(df)
st.button('Reload')
if __name__ == '__main__':
main()
上記を実行すると以下のような表示が得られる。
実際、ボタンを押すと表示内容が変わるはず。
ポイントは、Streamlit は毎回スクリプトを評価し直すように動作するところ。
つまり、ウィジェットで何らかのイベントが起こったら、Streamlit はページの内容を丸ごと評価し直すと考えれば良い。
上記のサンプルコードは、ボタンが押されるイベントによって、表示が丸ごと変わったわけだ。
ウィジェットは、一番最後の試行 (評価) のときに、ウィジェットがどのような状態になったかを返す場合がある。
ボタンも同様で、最後の試行でボタンが押されたか・押されていないかを真偽値 (bool) で返す。
ウィジェットの特性を利用すると、ウィジェットを設置する関数から返ってくる値を使ってインタラクティブな画面が作れる。
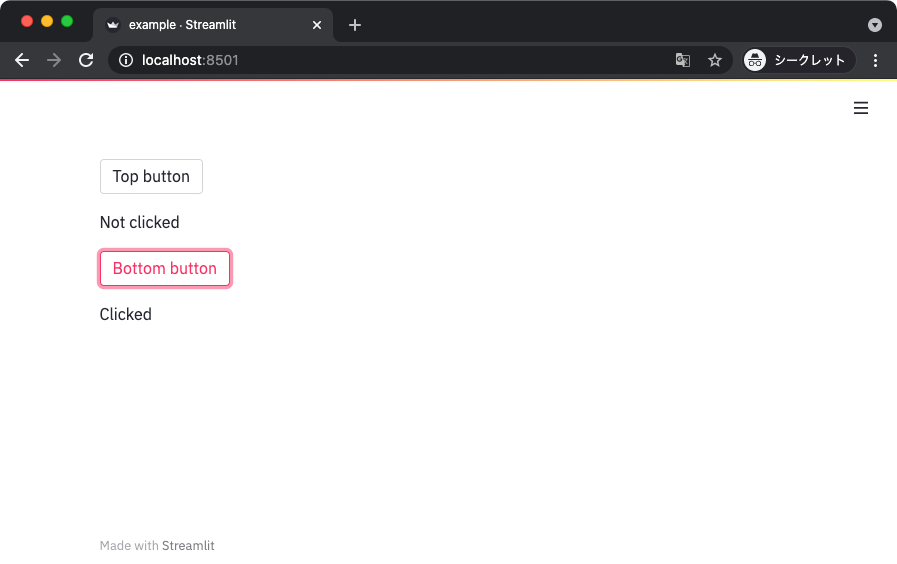
以下のサンプルコードでは、2 つのボタンを設置して、押されたボタンに対応するメッセージを表示している。
import streamlit as st
def main():
if st.button('Top button'):
st.write('Clicked')
else:
st.write('Not clicked')
if st.button('Bottom button'):
st.write('Clicked')
else:
st.write('Not clicked')
if __name__ == '__main__':
main()
上記を実行すると、以下のような表示が得られる。
ボタンを押すと、表示が更新されて、押されたボタンに対応するメッセージが表示されるはず。
チェックボックス
チェックボックスは、最後の試行でチェックされたか・されなかったかを元に処理を分岐できる。
以下のサンプルコードでは、チェックされたときだけデータフレームを表示している。
import streamlit as st
import pandas as pd
import numpy as np
def main():
if st.checkbox('Show'):
data = np.random.randn(20, 3)
df = pd.DataFrame(data, columns=['x', 'y', 'z'])
st.dataframe(df)
if __name__ == '__main__':
main()
上記を実行すると、以下のような表示が得られる。
チェックボックスをチェックしたときだけデータフレームが表示される。
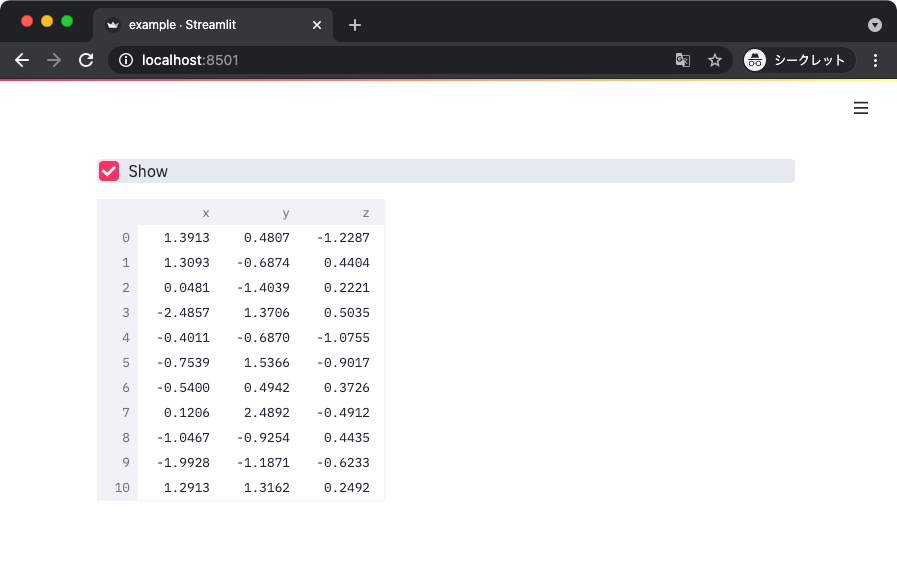
ラジオボタン
同様に、最後の試行でチェックされたアイテムを元に処理をできるラジオボタン。
import streamlit as st
def main():
selected_item = st.radio('Which do you like?',
['Dog', 'Cat'])
if selected_item == 'Dog':
st.write('Wan wan')
else:
st.write('Nya- nya-')
if __name__ == '__main__':
main()
上記を実行して得られる表示は以下のとおり。
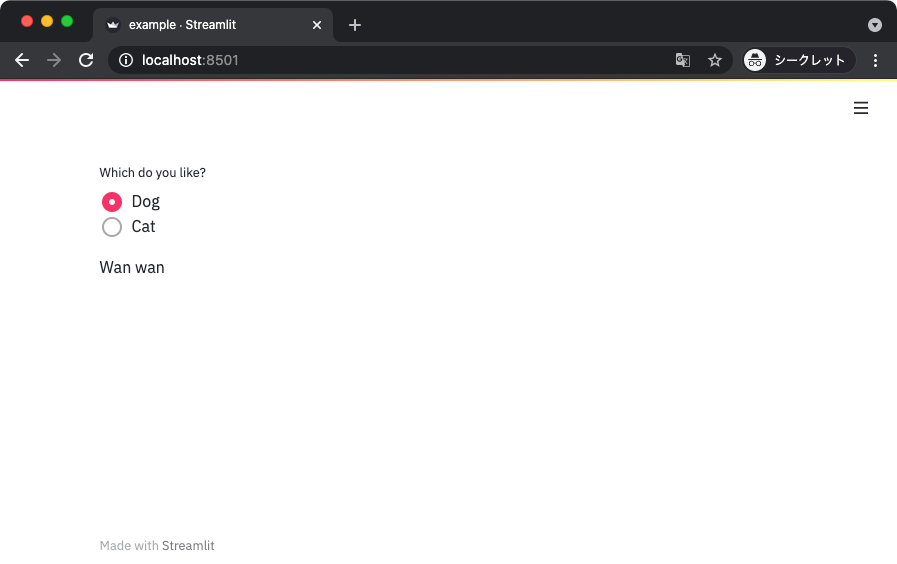
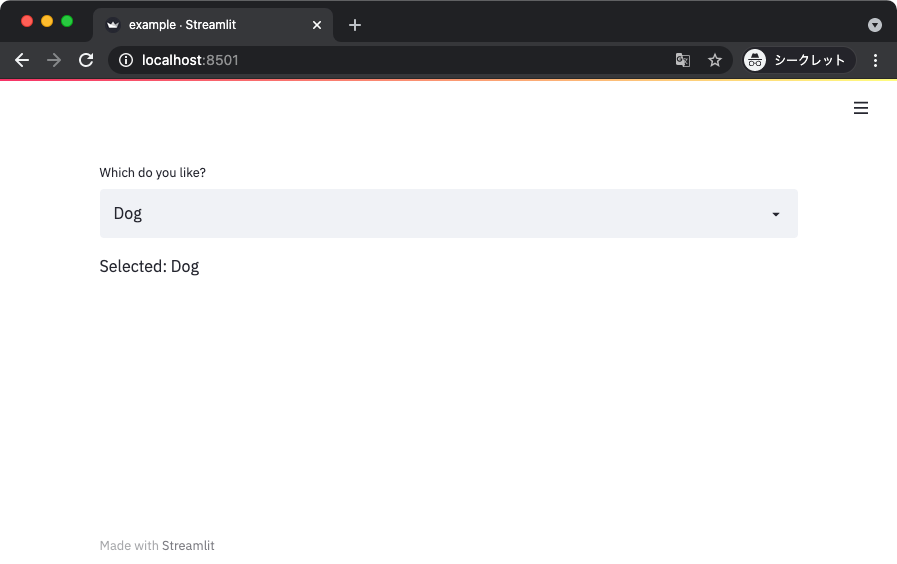
セレクトボックス
できることは基本的にラジオボタンと変わらないセレクトボックス。
import streamlit as st
def main():
selected_item = st.selectbox('Which do you like?',
['Dog', 'Cat'])
st.write(f'Selected: {selected_item}')
if __name__ == '__main__':
main()
上記を実行して得られる表示は以下のとおり。
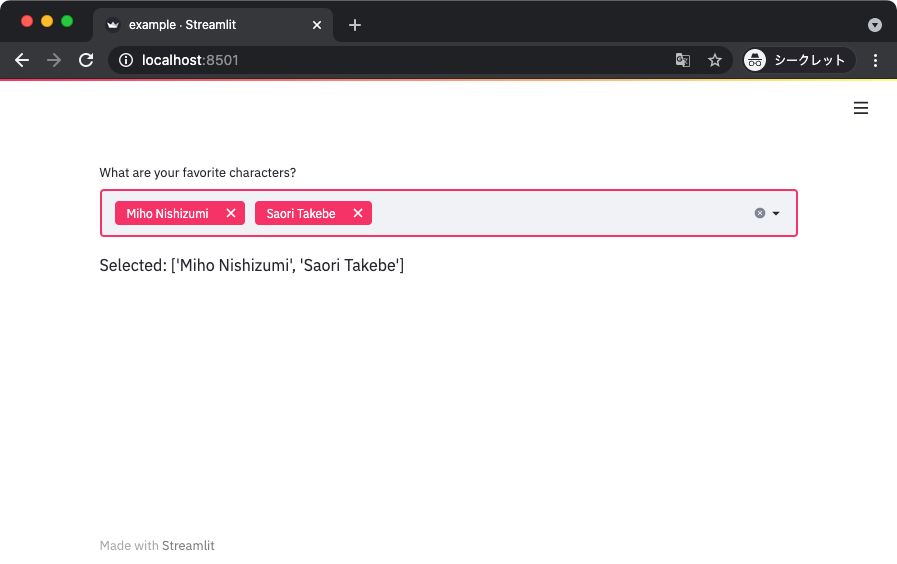
単一のアイテムを選択するセレクトボックスの他に、複数のアイテムを選択できるマルチセレクトもある。
import streamlit as st
def main():
selected_items = st.multiselect('What are your favorite characters?',
['Miho Nishizumi',
'Saori Takebe',
'Hana Isuzu',
'Yukari Akiyama',
'Mako Reizen',
])
st.write(f'Selected: {selected_items}')
if __name__ == '__main__':
main()
上記から得られる表示は以下のとおり。
スライダー
スライダーは特定の範囲の中から値を選択するのに使える。
import streamlit as st
def main():
age = st.slider(label='Your age',
min_value=0,
max_value=130,
value=30,
)
st.write(f'Selected: {age}')
if __name__ == '__main__':
main()
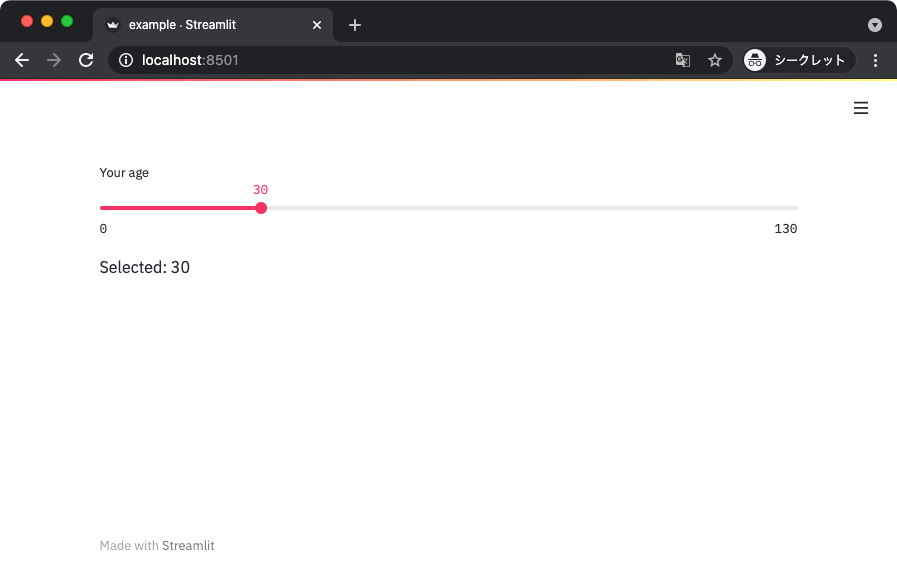
デフォルトの値にタプルなどで 2 つの要素を指定すると、レンジを入力できるようになる。
import streamlit as st
def main():
min_value, max_value = st.slider(label='Range selected',
min_value=0,
max_value=100,
value=(40, 60),
)
st.write(f'Selected: {min_value} ~ {max_value}')
if __name__ == '__main__':
main()
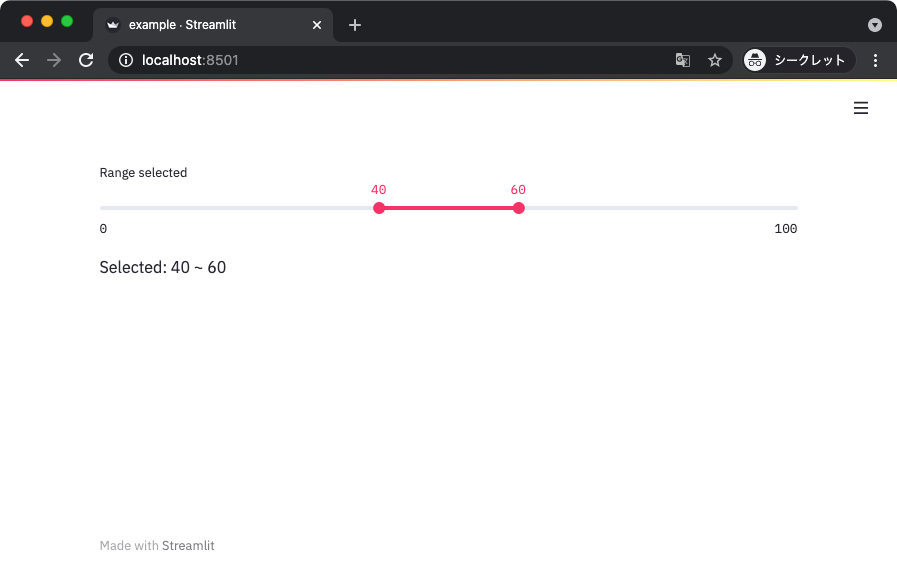
ちなみに整数以外にも日付とかを指定するのにも使える。
ただ、そんなに使いやすいとは思えない。
日付とか時間は後述する専用のウィジェットを使った方が良いと思う。
from datetime import date
import streamlit as st
def main():
birthday = st.slider('When is your birthday?',
min_value=date(1900, 1, 1),
max_value=date.today(),
value=date(2000, 1, 1),
format='YYYY-MM-DD',
)
st.write('Birthday: ', birthday)
if __name__ == '__main__':
main()
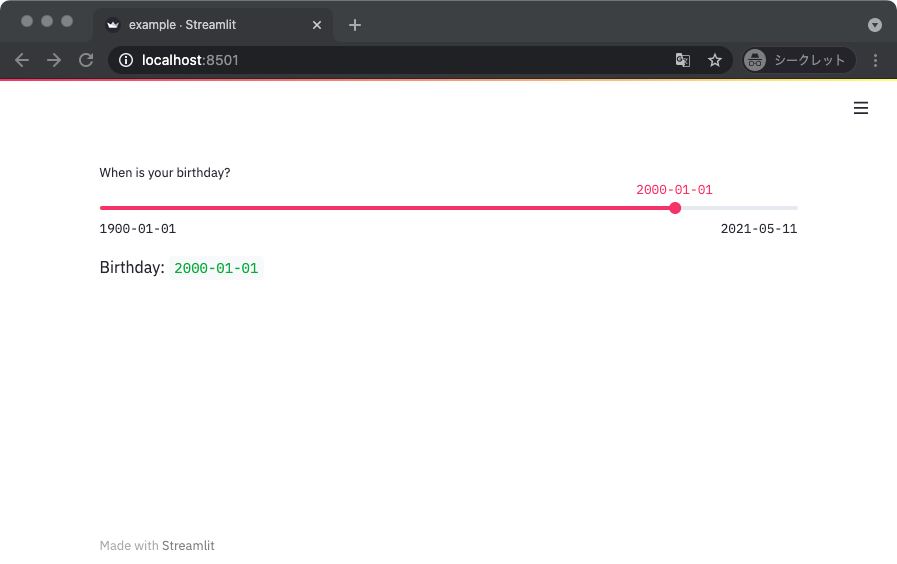
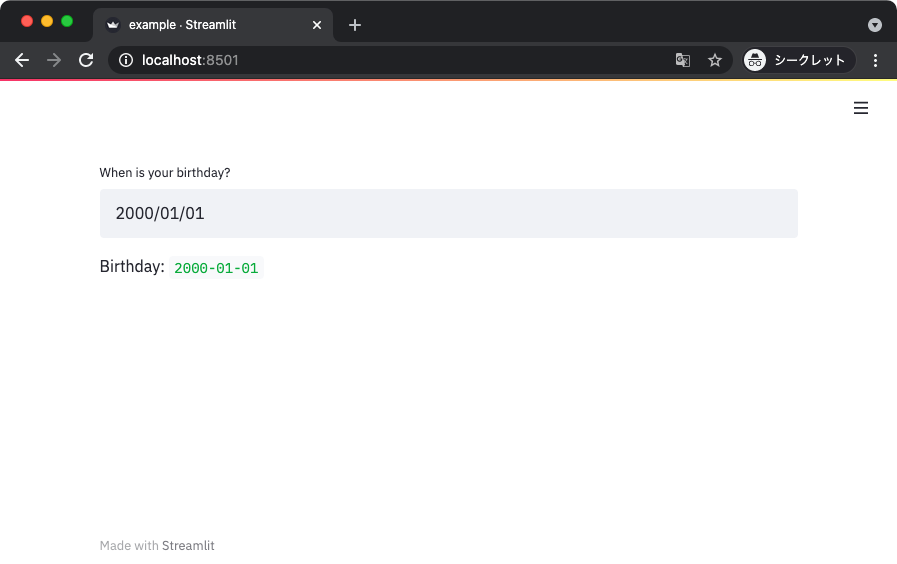
Date / Time インプット
日付や時間を扱う専用のウィジェットが続いて紹介する Date / Time インプット。
まずは Date インプットから。
from datetime import date
import streamlit as st
def main():
birthday = st.date_input('When is your birthday?',
min_value=date(1900, 1, 1),
max_value=date.today(),
value=date(2000, 1, 1),
)
st.write('Birthday: ', birthday)
if __name__ == '__main__':
main()
ウィジェットをクリックするとカレンダーで日付を指定できるので使いやすい。
Time インプットは一日の中の時間を指定できる。
import streamlit as st
def main():
time = st.time_input(label='Your input:')
st.write('input: ', time)
if __name__ == '__main__':
main()
こちらもウィジェットをクリックすると時間のセレクタが表示されて使いやすい。
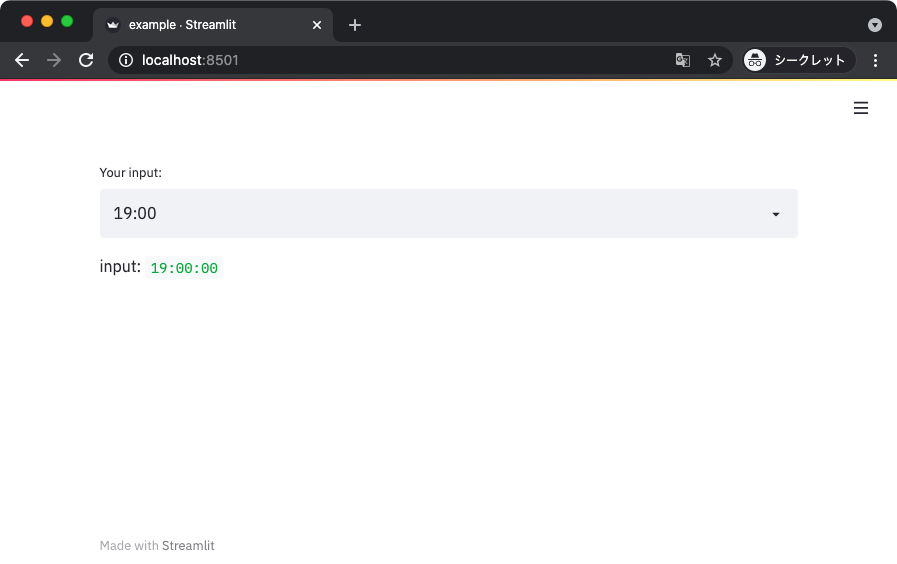
文字列入力
一行の文字列の入力にはテキストインプットが使える。
import streamlit as st
def main():
text = st.text_input(label='Message', value='Hello, World!')
st.write('input: ', text)
if __name__ == '__main__':
main()
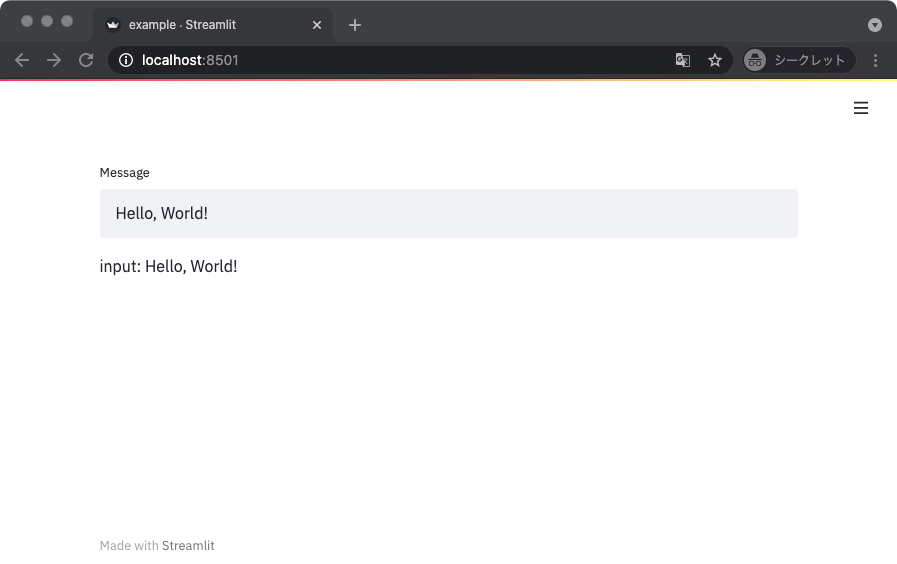
同様に、複数行に渡る文字列を入力するときはテキストエリアを用いる。
import streamlit as st
def main():
text = st.text_area(label='Multi-line message', value='Hello, World!')
st.write('input: ', text)
if __name__ == '__main__':
main()
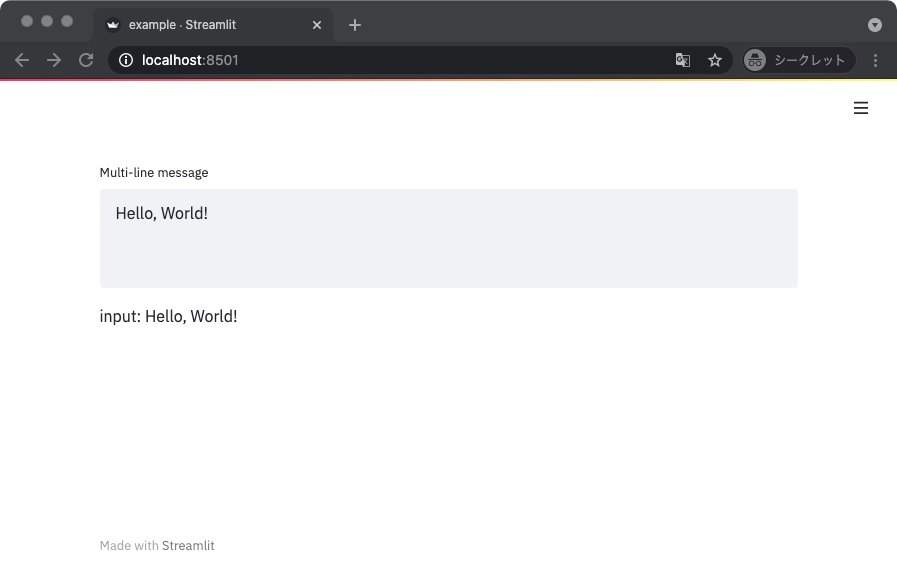
数字入力
数字を入力するときはナンバーインプットを使う。
import streamlit as st
def main():
n = st.number_input(label='What is your favorite number?',
value=42,
)
st.write('input: ', n)
if __name__ == '__main__':
main()
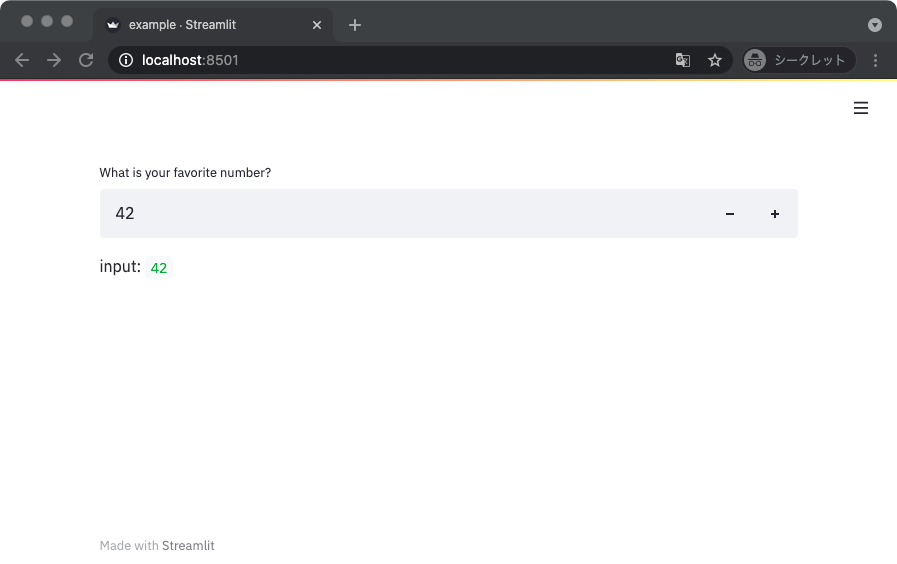
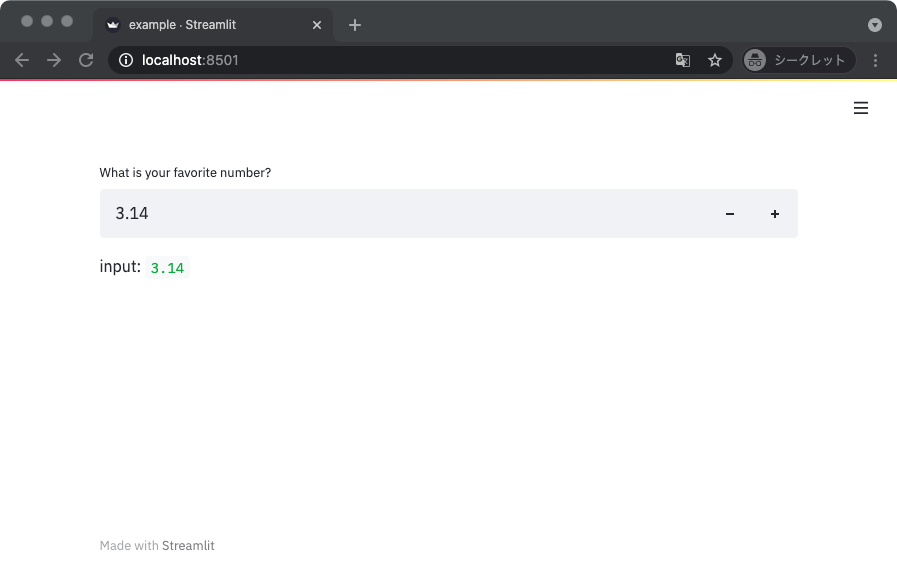
デフォルト値を浮動小数点型にすれば、小数を入力できる。
import streamlit as st
def main():
n = st.number_input(label='What is your favorite number?',
value=3.14,
)
st.write('input: ', n)
if __name__ == '__main__':
main()
ファイルアップローダ
ファイルアップローダを使うと、クライアントのファイルをアプリケーションに渡すことができる。
以下のサンプルコードでは、渡されたファイルに含まれるテキストを UTF-8 として表示している。
import streamlit as st
def main():
f = st.file_uploader(label='Upload file:')
st.write('input: ', f)
if f is not None:
XXX
data = f.getvalue()
text = data.decode('utf-8')
st.write('contents: ', text)
if __name__ == '__main__':
main()
適当なテキストファイルを使って動作確認してみよう。
$ echo "Hello, World" > ~/Downloads/greet.txt
ウィジェットをクリックしてファイルを選択すると、以下のように中身が表示される。
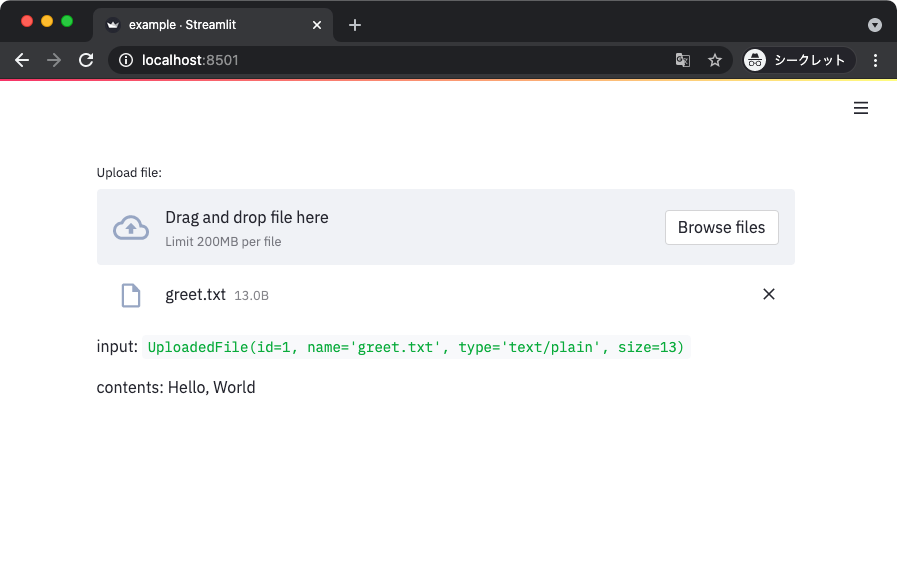
受け取れるオブジェクトは streamlit.UploadedFile という、オープン済みのファイルライクオブジェクトになる。
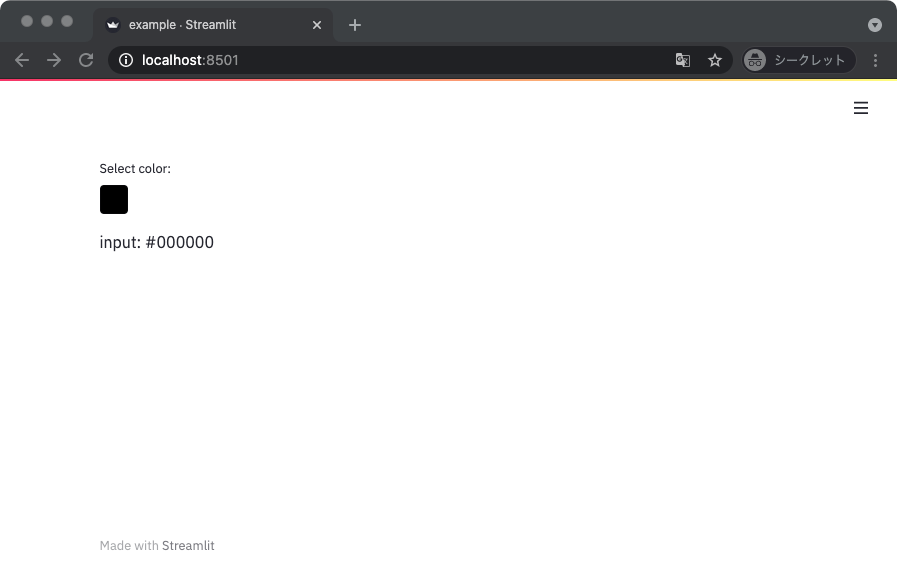
カラーピッカー
ちょっと変わり種だけどカラーピッカーも用意されている。
import streamlit as st
def main():
c = st.color_picker(label='Select color:')
st.write('input: ', c)
if __name__ == '__main__':
main()
フロー制御
ウィジェットが色々とあると、ユーザの入力のバリデーションも考えることになる。
ここではフロー制御をするための機能を紹介する。
特定の条件に満たないときに処理を停止するサンプルコードを以下に示す。
このサンプルではテキストインプットに何か文字列が入っていないときに警告メッセージを出して処理を停止している。
処理の停止には streamlit.stop() 関数を使う。
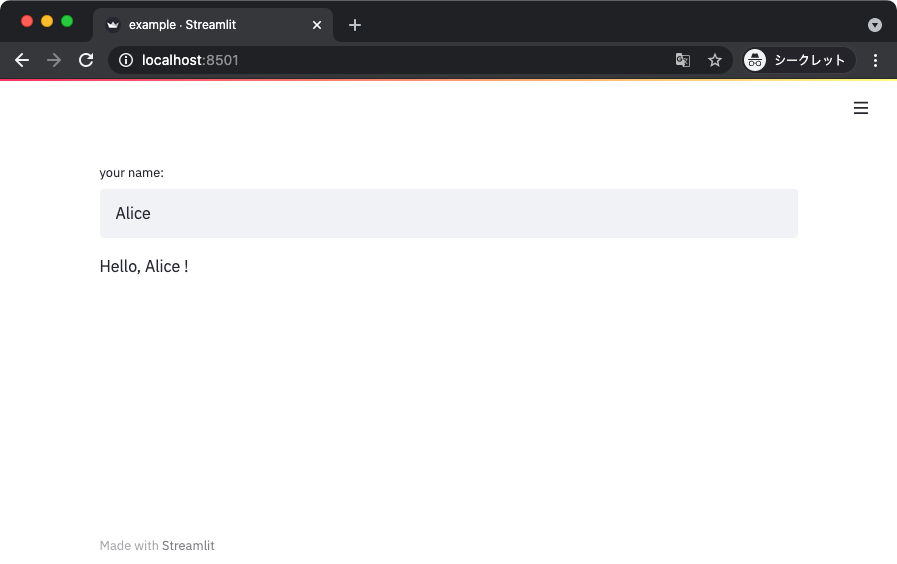
import streamlit as st
def main():
name = st.text_input(label='your name:')
if len(name) < 1:
st.warning('Please input your name')
st.stop()
st.write('Hello,', name, '!')
if __name__ == '__main__':
main()
テキストインプットに何も入力されていない状態では、以下のように警告メッセージだけが表示されることになる。
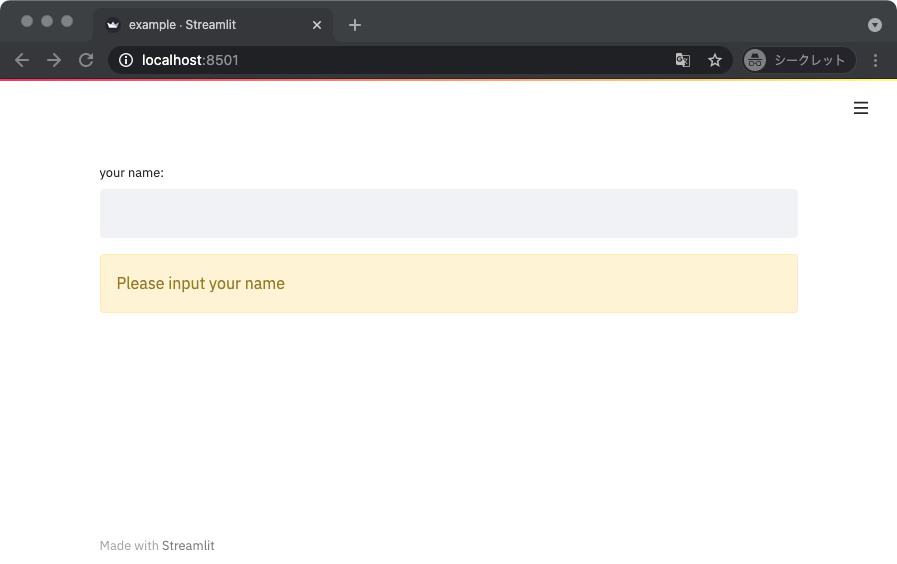
テキストインプットに文字列を入力すると、警告メッセージが消えて正常系の表示に切り替わる。
レイアウトを調整する
ここからは画面のレイアウトを調整するための機能を見ていく。
カラム
はじめに紹介するのはカラム。
これは、ようするに画面を縦方向に分割して異なる内容を表示できるもの。
カラムを作るには streamlit.beta_columns() 関数を使う。
以下のサンプルコードでは画面を 3 列に分割している。
関数の返り値をコンテキストマネージャとして使うとデフォルトの出力先として使うこともできるし、オブジェクトに直接書き込むこともできる。
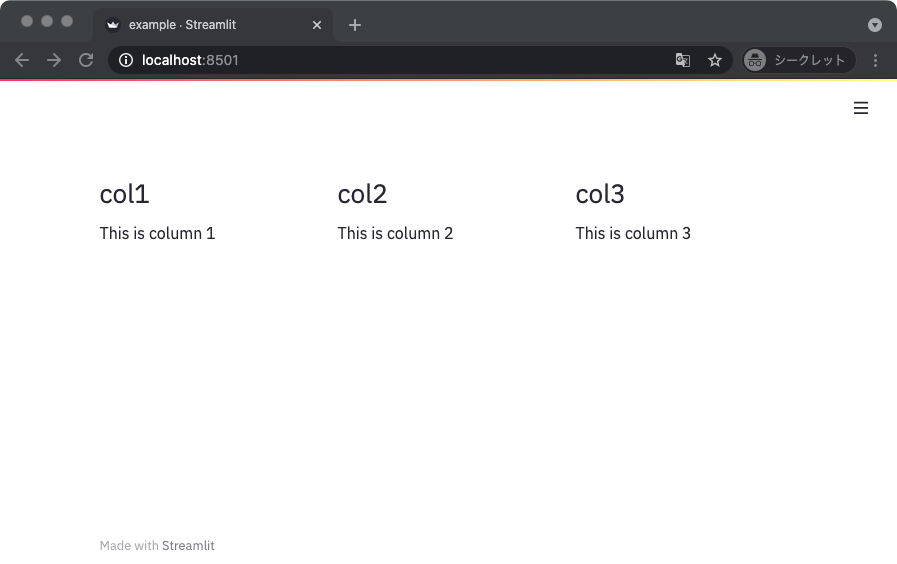
import streamlit as st
def main():
col1, col2, col3 = st.beta_columns(3)
with col1:
st.header('col1')
with col2:
st.header('col2')
with col3:
st.header('col3')
col1.write('This is column 1')
col2.write('This is column 2')
col3.write('This is column 3')
if __name__ == '__main__':
main()
上記を実行して得られる表示は以下のとおり。
コンテナ
続いて扱うのはコンテナ。
これは、不可視な仕切りみたいなもの。
以下のサンプルコードではコンテナの内と外にオブジェクトを書き込んで、結果を確認している。
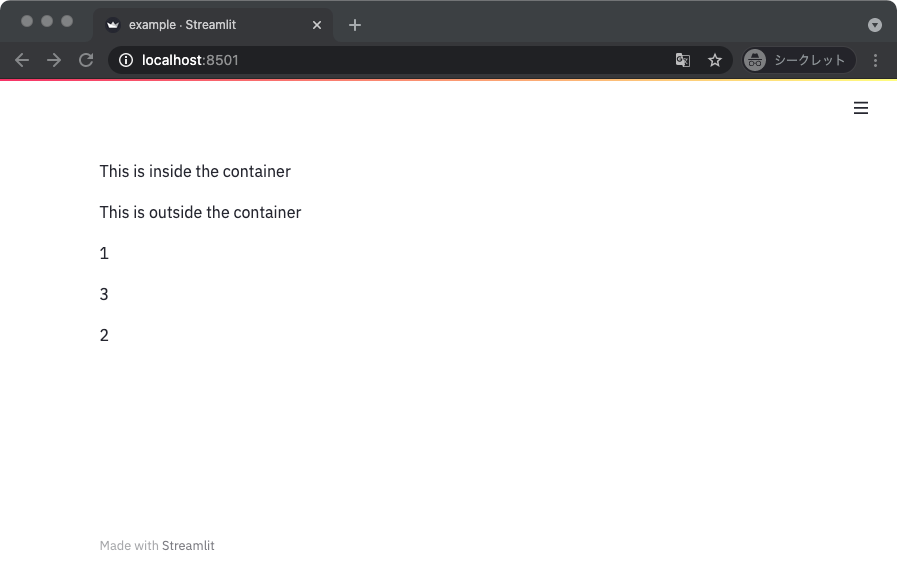
import streamlit as st
def main():
container = st.beta_container()
with container:
st.write('This is inside the container')
st.write('This is outside the container')
container = st.beta_container()
container.write('1')
st.write('2')
container.write('3')
if __name__ == '__main__':
main()
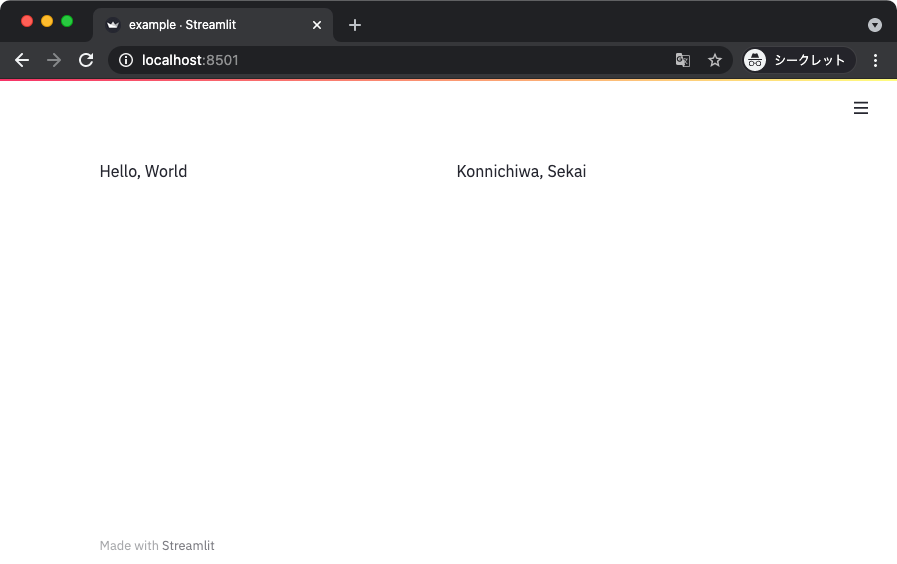
入れ子にすることもできて、たとえば以下のサンプルコードではプレースホルダにコンテナを追加して、さらにそこにカラムを追加している。
import streamlit as st
def main():
placeholder = st.empty()
container = placeholder.beta_container()
col1, col2 = container.beta_columns(2)
with col1:
st.write('Hello, World')
with col2:
st.write('Konnichiwa, Sekai')
if __name__ == '__main__':
main()
エキスパンダ
デフォルトでは折りたたまれて非表示な領域を作るのにエキスパンダが使える。
import streamlit as st
def main():
with st.beta_expander('See details'):
st.write('Hidden item')
if __name__ == '__main__':
main()
上記を実行して、以下はエキスパンダを展開した状態。
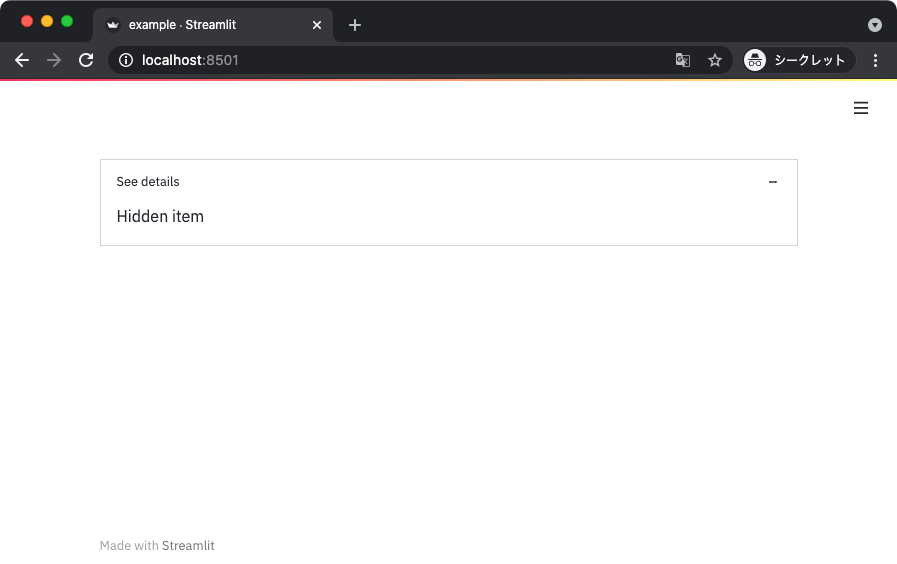
サイドバー
ウィジェットやオブジェクトの表示をサイドバーに配置することもできる。
使い方は単純で、サイドバーに置きたいなと思ったら sidebar をつけて API を呼び出す。
以下のサンプルコードでは、サイドバーにボタンを配置している。
前述したとおり、streamlit.button() を streamlit.sidebar.button() に変えるだけ。
同様に、streamlit.sidebar.dataframe() のように間に sidebar をはさむことで大体の要素はサイドバーに置ける。
import streamlit as st
import pandas as pd
import numpy as np
def main():
st.sidebar.button('Reload')
data = np.random.randn(20, 3)
df = pd.DataFrame(data, columns=['x', 'y', 'z'])
st.sidebar.dataframe(df)
if __name__ == '__main__':
main()
上記を実行すると、以下のようにサイドバーに要素が設置されることが確認できる。
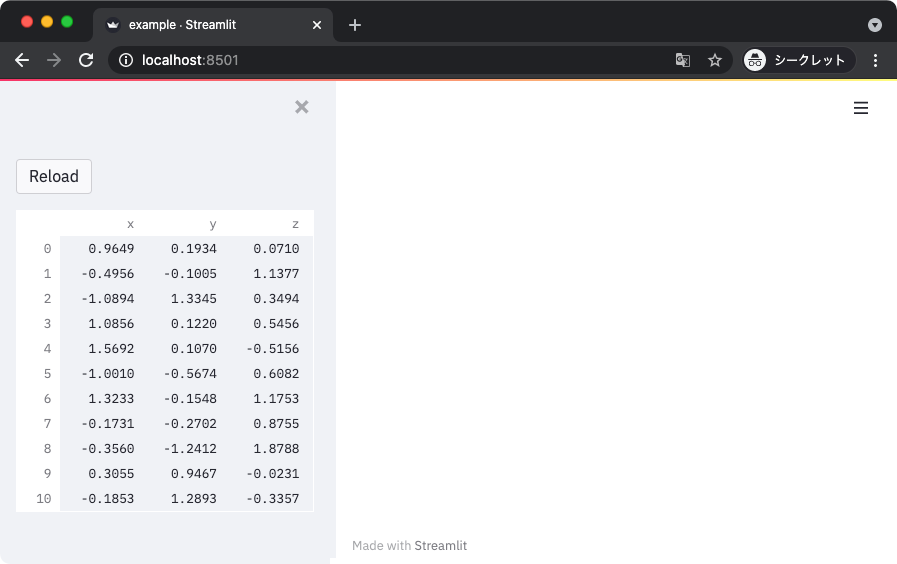
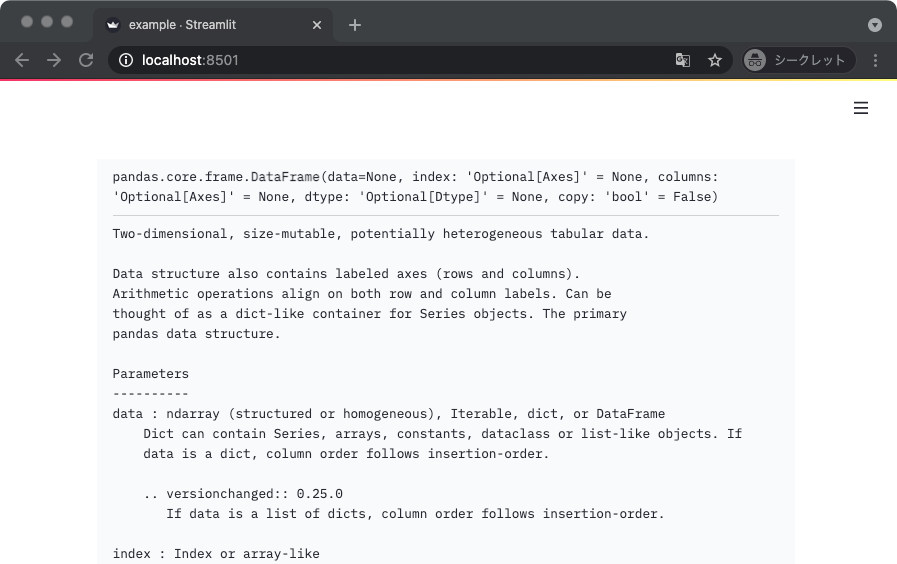
オブジェクトの docstring を表示する
Streamlit はスクリプトの変更を検出して自動でリロードしてくれるため、基本的には WebUI を見ながら開発していくことになる。
そんなとき、この関数またはメソッドの使い方なんだっけ?みたいな場面では streamlit.help() を使うと良い。
オブジェクトの docstring を表示してくれる。
import pandas as pd
import streamlit as st
def main():
st.help(pd.DataFrame)
if __name__ == '__main__':
main()
まあ自動補完とかドキュメント表示をサポートしてる IDE なんかで開発するときは、あんまり使わないかもしれないけど。
単一のスクリプトで複数のアプリケーションを扱う
Streamlit は基本的に複数のページから成るアプリケーションを作ることができない。
では、複数のアプリケーションを単一のスクリプトで扱うことができないか、というとそうではない。
これは、ウィジェットの状態に応じて表示するアプリケーションを切り替えてやることで実現できる。
以下のサンプルコードでは、セレクトボックスの状態に応じて実行する関数を切り替えている。
それぞれの関数が、それぞれのアプリケーションになっていると考えてもらえれば良い。
import streamlit as st
def render_gup():
"""GuP のアプリケーションを処理する関数"""
character_and_quotes = {
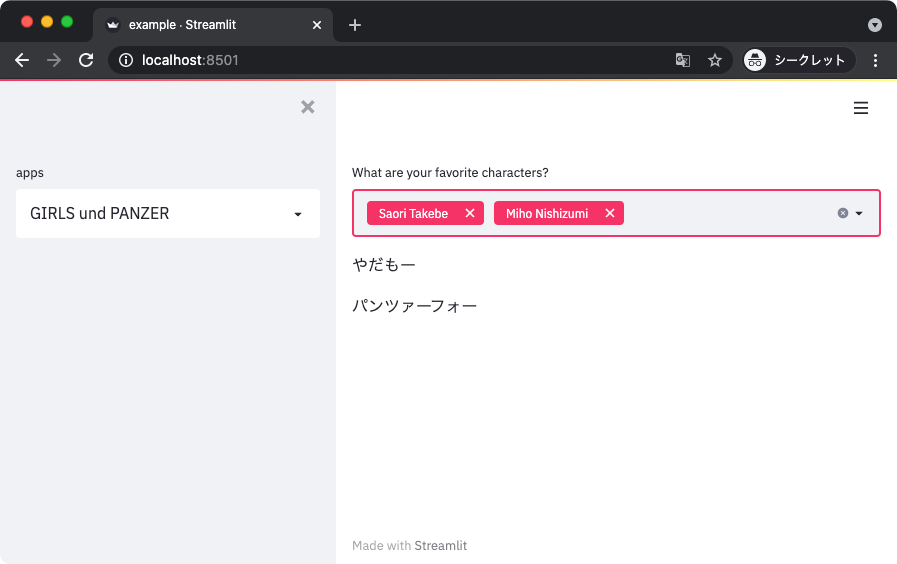
'Miho Nishizumi': 'パンツァーフォー',
'Saori Takebe': 'やだもー',
'Hana Isuzu': '私この試合絶対勝ちたいです',
'Yukari Akiyama': '最高だぜ!',
'Mako Reizen': '以上だ',
}
selected_items = st.multiselect('What are your favorite characters?',
list(character_and_quotes.keys()))
for selected_item in selected_items:
st.write(character_and_quotes[selected_item])
def render_aim_for_the_top():
"""トップ!のアプリケーションを処理する関数"""
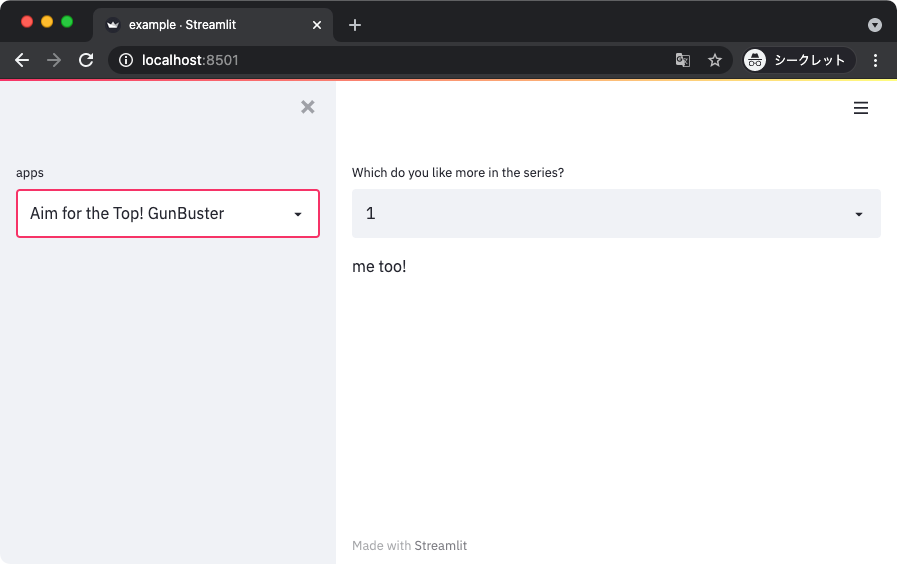
selected_item = st.selectbox('Which do you like more in the series?',
[1, 2])
if selected_item == 1:
st.write('me too!')
else:
st.write('2 mo ii yo ne =)')
def main():
apps = {
'-': None,
'GIRLS und PANZER': render_gup,
'Aim for the Top! GunBuster': render_aim_for_the_top,
}
selected_app_name = st.sidebar.selectbox(label='apps',
options=list(apps.keys()))
if selected_app_name == '-':
st.info('Please select the app')
st.stop()
render_func = apps[selected_app_name]
render_func()
if __name__ == '__main__':
main()
上記を実行して得られる表示を以下に示す。
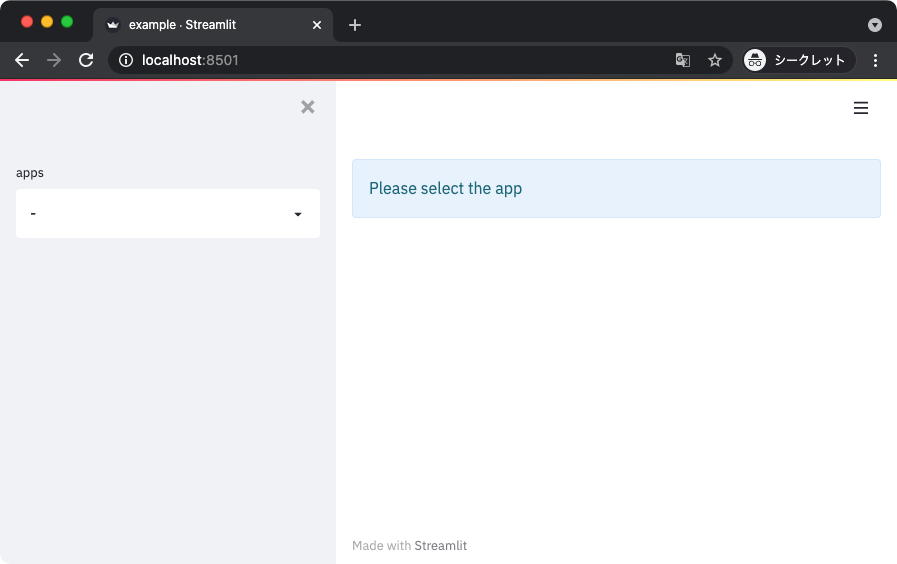
ちなみに、呼び出す関数も 1 つのスクリプトにまとまっている必要はない。
別のモジュールに切り出して、スクリプトではそれをインポートして使うこともできる。
それならコードの見通しもさほど悪くはならないはず。
スクリプトでコマンドライン引数を受け取る
Streamlit のスクリプトにコマンドライン引数を渡したいときもある。
ここでは、そのやり方を紹介する。
Argparse
まずは Python の標準ライブラリにある Argparse を使う場合。
スクリプトを書く時点では特に Streamlit かどうかを意識する必要はない。
一般的な使い方と同じように引数を設定してパースして使うだけ。
import argparse
import streamlit as st
def main():
parser = argparse.ArgumentParser(description='parse argument example')
parser.add_argument('--message', '-m', type=str, default='World')
args = parser.parse_args()
st.write(f'Hello, {args.message}!')
if __name__ == '__main__':
main()
ただ、使う時点ではちょっと注意点がある。
スクリプトの後ろにオプションをつけると Streamlit の引数として認識されてしまう。
$ streamlit run example.py -m Sekai
Usage: streamlit run [OPTIONS] TARGET [ARGS]...
Try 'streamlit run --help' for help.
Error: no such option: -m
そこで -- を使って区切って、スクリプトに対する引数であることを明示的に示す。
$ streamlit run example.py -- -m Sekai
Click
続いてサードパーティ製のパッケージである Click を使う場合。
Click は純粋なコマンドラインパーサ以外の機能もあることから、スクリプトを記述する時点から注意点がある。
具体的には、デコレータで修飾したオブジェクトを呼び出すときに standalone_mode を False に指定する。
こうすると、デフォルトでは実行が完了したときに exit() してしまう振る舞いを抑制できる。
import streamlit as st
import click
@click.command()
@click.option('--message', '-m', type=str, default='World')
def main(message):
st.write(f'Hello, {message}!')
if __name__ == '__main__':
main(standalone_mode=False)
実行するときに Streamlit のオプションとの間に -- で区切りが必要なのは Argparse のときと同じ。
$ streamlit run example.py -- -m Sekai
参考
docs.streamlit.io
click.palletsprojects.com






")