ニューラルネットワークの並列計算には、今や GPU や TPU を使うのが一般的になっている。
一方で、それらのデバイスにデータを供給する部分がボトルネックにならないよう気をつけなければいけない。
具体的には、デバイスが計算している最中に、次に計算するデータを用意しておく必要がある。
今回は、TensorFlow で効率的なデータ供給を実現するために用意された Dataset API を試してみる。
使った環境は次のとおり。
$ sw_vers
ProductName: macOS
ProductVersion: 11.2.1
BuildVersion: 20D74
$ python -V
Python 3.8.7
$ pip list | grep "tensorflow "
tensorflow 2.4.1
もくじ
下準備
あらかじめ、TensorFlow をインストールしておく。
$ pip install tensorflow
インストールできたら Python の REPL を起動する。
$ python
そして、TensorFlow をインポートする。
>>> import tensorflow as tf
Dataset API について
Dataset API を使うと、TensorFlow/Keras で定義したモデルに対して、効率的に Tensor を供給するためのパイプライン処理が記述できる。
たとえば、tensorflow.keras.Model の fit() メソッドには NumPy 配列や Tensor オブジェクト以外にも、Dataset というオブジェクトを渡すことができる。
www.tensorflow.org
Dataset オブジェクトの作り方
Dataset オブジェクトはいくつかの作り方がある。
Dataset.range()
一番シンプルなのが Dataset.range() を使うやり方かな。
これはおそらくパイプラインをデバッグするときに活躍する。
>>> ds = tf.data.Dataset.range(1, 6)
>>> ds
<RangeDataset shapes: (), types: tf.int64>
Dataset オブジェクトはイテラブルなので iter() 関数を使うとイテレータが返ってくる。
>>> it = iter(ds)
>>> it
<tensorflow.python.data.ops.iterator_ops.OwnedIterator object at 0x14cd26d30>
イテレータに対して next() を使うと、Tensor オブジェクトが得られる。
>>> next(it)
<tf.Tensor: shape=(), dtype=int64, numpy=1>
>>> next(it)
<tf.Tensor: shape=(), dtype=int64, numpy=2>
>>> next(it)
<tf.Tensor: shape=(), dtype=int64, numpy=3>
中身を一通り確認したいときは as_numpy_iterator() メソッドを使うのが楽かな。
>>> list(ds.as_numpy_iterator())
[1, 2, 3, 4, 5]
Dataset.from_tensor_slices()
既存の配列や辞書なんかから作りたいときは Dataset.from_tensor_slices() を使うと良い。
たとえば、配列から作るときはこんな感じ。
>>> slices = tf.data.Dataset.from_tensor_slices([2, 3, 5, 7, 11])
>>> list(slices.as_numpy_iterator())
[2, 3, 5, 7, 11]
多次元のときはタプルか配列でネストする。
>>> slices = tf.data.Dataset.from_tensor_slices([(1, 1), (2, 3), (5, 8), (13, 21)])
>>> list(slices.as_numpy_iterator())
[array([1, 1], dtype=int32), array([2, 3], dtype=int32), array([5, 8], dtype=int32), array([13, 21], dtype=int32)]
単純な Tensor だけでなく、辞書にネストした Tensor を要素として返すこともできるらしい。
>>> elements = {
... 'x': ([1, 4, 7], [2, 5, 8]),
... 'y': [3, 6, 9],
... }
>>> dict_ds = tf.data.Dataset.from_tensor_slices(elements)
>>> list(dict_ds.as_numpy_iterator())
[{'x': (1, 2), 'y': 3}, {'x': (4, 5), 'y': 6}, {'x': (7, 8), 'y': 9}]
Dataset.from_tensor()
既存の Tensor を流用する API としては Dataset.from_tensor() もある。
こちらは各 Tensor の形状が一致していなくてもエラーにならない。
>>> t1 = tf.constant([1, 2, 3])
>>> t2 = tf.constant([4, 5])
>>> ts_ds = tf.data.Dataset.from_tensors((t1, t2))
>>> list(ts_ds.as_numpy_iterator())
[(array([1, 2, 3], dtype=int32), array([4, 5], dtype=int32))]
Dataset.from_generator()
割とよく使いそうなのが Dataset.from_generator() で、これはジェネレータを元に Dataset オブジェクトが作れる。
何か適当にジェネレータ関数を用意する。
>>> def g():
... yield 1
... yield 2
... yield 3
...
あとはそれを元に作れる。
ジェネレータをそのまま渡すと、一回読み出して終わりになってしまうので lambda 式と組み合わせるのが良いと思う。
>>> g_ds = tf.data.Dataset.from_generator(lambda: g(), output_types=tf.uint32)
>>> list(g_ds.as_numpy_iterator())
[1, 2, 3]
多次元だったりデータ型が複合的なときはこんな感じ。
>>> def g():
... yield ('a', 1)
... yield ('b', 2)
... yield ('c', 3)
...
>>> g_ds = tf.data.Dataset.from_generator(lambda: g(), output_types=(tf.string, tf.uint32))
>>> list(g_ds.as_numpy_iterator())
[(b'a', 1), (b'b', 2), (b'c', 3)]
Dataset.list_files()
ファイルを元に Dataset オブジェクトを作りたいときは Dataset.list_files() を使うのが便利そう。
たとえばカレンとワーキングディレクトリに、次のようにテキストファイルを用意しておく。
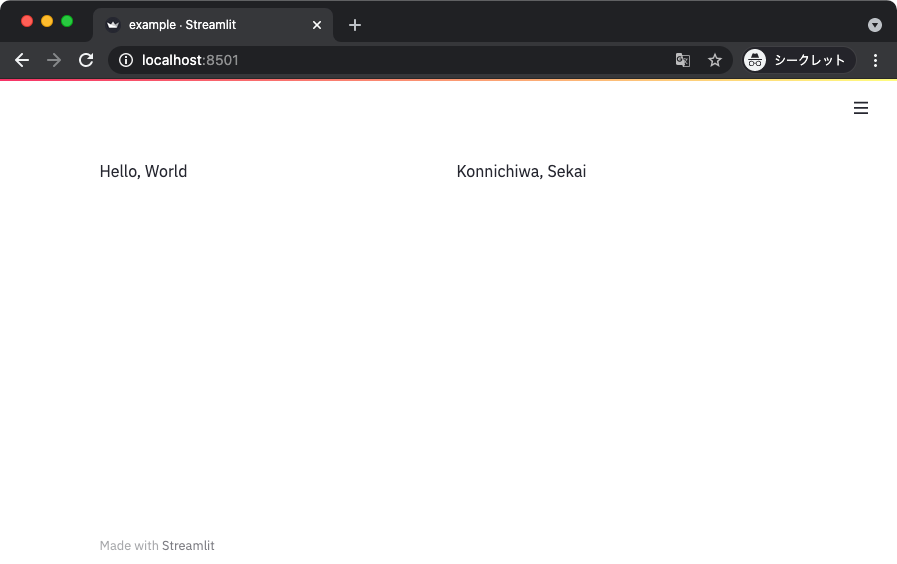
$ echo "Hello, World" > greet.txt
$ echo "Konnichiwa, Sekai" > aisatsu.txt
Dataset.list_files() にファイル名のパターンを入れると、それに該当するファイル名が抽出される。
>>> files_ds = tf.data.Dataset.list_files('*.txt')
>>> list(files_ds.as_numpy_iterator())
[b'./aisatsu.txt', b'./greet.txt']
例えば、これを後述する map() とかで処理すると並列化が楽にできる。
基本的な情報を得る
Dataset オブジェクトには、基本的な情報を得るためのアトリビュートがいくつかある。
Dataset#elementspec
たとえば、得られるデータの形状や型は elementspec というプロパティで確認できる。
>>> ds.element_spec
TensorSpec(shape=(), dtype=tf.int64, name=None)
Dataset#cardinality()
サイズが固定だったり、いくつかの条件を満たすときは cardinality() というメソッドで要素の種類が得られる。
>>> ds.cardinality()
<tf.Tensor: shape=(), dtype=int64, numpy=5>
len()
Dataset オブジェクトのサイズも、あらかじめ分かっているときに関しては得られる。
>>> len(ds)
5
とはいえ、加工するとすぐに得られなくなるので使い所はなかなか難しい。
>>> len(ds.repeat())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/amedama/.virtualenvs/py38/lib/python3.8/site-packages/tensorflow/python/data/ops/dataset_ops.py", line 452, in __len__
raise TypeError("dataset length is infinite.")
TypeError: dataset length is infinite.
データセットを加工する
ここでは、Dataset オブジェクトを加工する方法について書く。
加工には、関数型プログラミング的なインターフェースが用意されている。
Dataset#filter()
特定の条件を満たす要素だけを残したいときには filter() メソッドを使う。
以下は偶数の要素だけを抽出する例。
>>> even_ds = ds.filter(lambda x: x % 2 == 0)
>>> list(even_ds.as_numpy_iterator())
[2, 4]
Dataset#reduce()
要素を集約したいときは reduce() メソッドが使える。
以下は要素をすべて足していく例。
>>> ds.reduce(initial_state=tf.Variable(0, dtype=tf.int64),
... reduce_func=lambda cumulo, current: cumulo + current)
<tf.Tensor: shape=(), dtype=int64, numpy=15>
Dataset#map()
すべての要素に処理を適用したいときは map() メソッドを使う。
以下はすべての要素を 2 倍する例。
>>> double_ds = ds.map(lambda x: x * 2)
>>> list(double_ds.as_numpy_iterator())
[2, 4, 6, 8, 10]
map() メソッドは処理を並列化できる。
並列度は num_parallel_calls オプションで指定する。
また、順序を保持する必要があるかを deterministic オプションで指定する。
以下は、4 並列で順序を保持しない場合の例。
>>> double_ds = ds.map(lambda x: x * 2, num_parallel_calls=4, deterministic=False)
>>> list(double_ds.as_numpy_iterator())
[4, 2, 6, 8, 10]
2 と 4 の順番が入れ替わっていることがわかる。
パフォーマンスを追い求めるときは deterministic=False が推奨されている。
また、並列度をランタイムで良い感じに決めてほしいときは tf.data.AUTOTUNE という定数を指定すれば良いっぽい。
>>> ds.map(lambda x: x * 2, num_parallel_calls=tf.data.AUTOTUNE, deterministic=False)
Dataset#flat_map()
要素が入れ子構造になっているときに、開きながら処理したいときは flat_map() を使うと良い。
例えば、次のような 2 次元の要素を返す Dataset があったとする。
>>> nested_ds = tf.data.Dataset.from_tensor_slices([[1, 2], [3, 4], [5, 6]])
>>> list(nested_ds.as_numpy_iterator())
[array([1, 2], dtype=int32), array([3, 4], dtype=int32), array([5, 6], dtype=int32)]
ただ単に flatten したいなら、次のように関数の中で Dataset オブジェクトを返すようにする。
>>> flatten_ds = nested_ds.flat_map(lambda x: tf.data.Dataset.from_tensor_slices(x))
>>> list(flatten_ds.as_numpy_iterator())
[1, 2, 3, 4, 5, 6]
flatten して、さらに各要素に処理をしたいなら、メソッドチェーンしてこんな感じ。
もちろん、flatten した Dataset オブジェクトに map() メソッドを呼んでも良いんだけど。
>> flatten_double_ds = nested_ds.flat_map(lambda x: tf.data.Dataset.from_tensor_slices(x).map(lambda x: x * 2))
>>> list(flatten_double_ds.as_numpy_iterator())
[2, 4, 6, 8, 10, 12]
Dataset#interleave()
flat_map() の並列化版とでもいえるようなのが interleave() メソッド。
先ほどと同じように、ただ flatten するような処理をしてみよう。
>>> flatten_ds = nested_ds.interleave(lambda x: tf.data.Dataset.from_tensor_slices(x))
>>> list(flatten_ds.as_numpy_iterator())
[1, 3, 5, 2, 4, 6]
すると、要素の順番が入れ替わっていることがわかる。
これは、デフォルトで処理が並列化されているため。
interleave() と同じ結果にしたいときは cycle_length を 1 に指定する必要がある。
>>> flatten_ds = nested_ds.interleave(lambda x: tf.data.Dataset.from_tensor_slices(x), cycle_length=1)
>>> list(flatten_ds.as_numpy_iterator())
[1, 2, 3, 4, 5, 6]
cycle_length って何よ?って話になるんだけど、これは Dataset オブジェクトをキューのように処理する (仮想的な) Consumer の数を指している。
例えば、cycle_length が 2 のときは、キューが交互に処理されていくということ。
もちろん、新しい Dataset オブジェクトに要素が積まれる順番は早いもの勝ち。
試しに cycle_length=2 で処理してみよう。
>>> flatten_ds = nested_ds.interleave(lambda x: tf.data.Dataset.from_tensor_slices(x), cycle_length=2)
>>> list(flatten_ds.as_numpy_iterator())
[1, 3, 2, 4, 5, 6]
要素の順番が入れ替わった。
一度に処理する要素の数も block_length で指定できる。
試しに 2 を指定してみよう。
>>> flatten_ds = nested_ds.interleave(lambda x: tf.data.Dataset.from_tensor_slices(x), cycle_length=2, block_length=2)
>>> list(flatten_ds.as_numpy_iterator())
[1, 2, 3, 4, 5, 6]
結果からは分かりにくいけど、上記は [1, 2] -> [3, 4] -> [5, 6] という単位で処理されているはず。
ちょっとややこしいのは num_parallel_calls っていうオプションもあるところ。
ドキュメントによると、こちらのオプションに tf.data.AUTOTUNE を指定しておけば cycle_length は自動的に最大の並列度になるらしい。
>>> flatten_ds = nested_ds.interleave(lambda x: tf.data.Dataset.from_tensor_slices(x), num_parallel_calls=tf.data.AUTOTUNE, deterministic=False)
>>> list(flatten_ds.as_numpy_iterator())
[1, 3, 5, 2, 4, 6]
要するに、以下のように使えば複数のファイルを並列で処理できて良い感じってことみたい。
複数のテキストファイルに書かれている文章を、一つの Dataset オブジェクトとしてまとめる例。
>>> files_ds = tf.data.Dataset.list_files('*.txt')
>>> lines_ds = files_ds.interleave(lambda filepath: tf.data.TextLineDataset(filepath), num_parallel_calls=tf.data.AUTOTUNE, deterministic=False)
>>> list(lines_ds.as_numpy_iterator())
[b'Konnichiwa, Sekai', b'Hello, World']
いきなり tf.data.TextLineDataset が登場してるけど、これはテキストファイルを処理するために用意された Dataset オブジェクトの子クラス。
ファイルに書かれたテキストを一行ずつ読み出せる。
こういった、特定の処理に特化したクラスもいくつか用意されているが、ここでは詳しく扱わない。
Dataset#shuffle()
要素の順番を意図的に入れ替えたいときは shuffle() メソッドを使う。
ただし、ストリーミング的にデータを処理するので、バッファ単位でシャッフルすることになる。
バッファというのは、いわばキューのようなもので、そのキューの中で要素がランダムにシャッフルされる。
たとえば buffer_size が 1 なら、要素の順番は決して入れ替わらない。
>>> list(ds.shuffle(buffer_size=1).as_numpy_iterator())
[1, 2, 3, 4, 5]
buffer_size が 2 なら、要素の順番が入れ替わる。
ただし、最初の方にある要素が最後の方までいくのには、相当な運が必要になる。
なぜならシャッフルの処理で、そのままの位置にあっては取り出されてしまうため、連続で後ろに移動する必要がある。
>>> list(ds.shuffle(buffer_size=2).as_numpy_iterator())
[2, 1, 3, 5, 4]
そのため、バッファのサイズが大きいほど、より広い範囲で値が入れ替わりやすくなる。
>>> list(ds.shuffle(buffer_size=10).as_numpy_iterator())
[2, 1, 4, 3, 5]
Dataset#enumerate()
組み込み関数の enumerate() と同じ概念だけど、enumerate() メソッドを使うと連番の添字を付与できる。
>> enum_ds = ds.enumerate(start=100)
>>> list(enum_ds.as_numpy_iterator())
[(100, 1), (101, 2), (102, 3), (103, 4), (104, 5)]
Dataset#window()
window() メソッドを使うと、指定した数だけずらした要素が取れる。
活躍するとしたら、自然言語処理の分布仮説に関わる処理をするところかな。
例えば、1 つずらした要素を 2 つずつ得たい場合は次のようにする。
>>> shifted_ds = ds.window(size=2, shift=1)
window() メソッドはちょっとクセがあって、そのままだと as_numpy_iterator() メソッドが実行できない。
>>> shifted_ds.as_numpy_iterator()
Traceback (most recent call last):
...
TypeError: Dataset.as_numpy_iterator() does not support datasets containing <class 'tensorflow.python.data.ops.dataset_ops.DatasetV2'>
これは、Dataset オブジェクトから返る要素自体が Dataset オブジェクトになっているため。
なので、こんな感じで確認することになる。
>>> for window in shifted_ds:
... print(list(window.as_numpy_iterator()))
...
[1, 2]
[2, 3]
[3, 4]
[4, 5]
[5]
上記を見てわかるとおり、そのままだと末尾に size に満たない要素が得られてしまう。
これを避けるためには drop_remainder を有効にする。
>>> shifted_ds = ds.window(size=2, shift=1, drop_remainder=True)
>>> for window in shifted_ds:
... print(list(window.as_numpy_iterator()))
...
[1, 2]
[2, 3]
[3, 4]
[4, 5]
データ供給の効率を向上させる
ここでは Dataset を扱う上で、データ供給を効率的に行うために必要な処理を書いていく。
なお、処理を並列化する num_parallel_calls みたいなオプションについては、既にいくつかのメソッドで紹介した。
Dataset#prefetch()
Dataset オブジェクトの各要素は、イテレータから要素を取り出そうとするタイミングで評価される。
パイプラインが長大だとレイテンシが増加するので、prefetch() メソッドを使うことで先に読み込んでおくことができる。
>>> prefetched_ds = ds.prefetch(buffer_size=5)
>>> list(prefetched_ds.as_numpy_iterator())
[1, 2, 3, 4, 5]
Dataset#cache()
cache() メソッドを使うと、一度呼び出した Dataset オブジェクトの要素をファイルにキャッシュできる。
要素をシャッフルする加工が入ったパイプラインを使って動作を確認してみよう。
そのままだと、毎回シャッフルの処理が評価されるため得られる結果が異なる。
>>> shuffled_ds = ds.shuffle(buffer_size=10)
>>> list(shuffled_ds.as_numpy_iterator())
[4, 1, 2, 5, 3]
>>> list(shuffled_ds.as_numpy_iterator())
[5, 1, 4, 3, 2]
一方で cache() すると、一旦要素をすべて読み出し尽くした Dataset オブジェクトからは何度読んでも同じ順番で要素が返ってくる。
>>> cached_ds = shuffled_ds.cache()
>>> list(cached_ds.as_numpy_iterator())
[5, 1, 3, 4, 2]
>>> list(cached_ds.as_numpy_iterator())
[5, 1, 3, 4, 2]
ランダムな処理ではデータの多様性が失われる恐れはあるものの、時間のかかる処理がパイプラインに含まれるときには有効なはず。
cache() メソッドはお手軽な一方で、もうちょっと真面目にやるなら TFRecord 形式で永続化した方が良いかもしれない。
www.tensorflow.org
Dataset#shard()
データベースの負荷分散技術としてもよく知られているシャーディング。
shard() メソッドを使うと、データセットを複数に分割できる。
たぶん、分散学習とか複数のデバイスで学習するときに使われるんだと思う。
例えば、以下はシャード数に 2 を指定してデータセットを分割した場合。
>>> ds1of2 = ds.shard(num_shards=2, index=0)
>>> ds2of2 = ds.shard(num_shards=2, index=1)
確認すると、データが交互に分けられている。
>>> list(ds1of2.as_numpy_iterator())
[1, 3, 5]
>>> list(ds2of2.as_numpy_iterator())
[2, 4]
Dataset#batch()
現在のニューラルネットワークの学習で一般的に用いられるミニバッチ勾配降下法では、複数の要素をミニバッチという単位で読み込む。
batch() メソッドを使うと、Dataset オブジェクトからミニバッチの単位毎にデータを読み込めるようになる。
>>> batched_ds = ds.batch(3)
>>> list(batched_ds.as_numpy_iterator())
[array([1, 2, 3]), array([4, 5])]
drop_remainder を有効にすると、バッチサイズに満たない残りの要素は読み出されなくなる。
>>> batched_ds = ds.batch(3, drop_remainder=True)
>>> list(batched_ds.as_numpy_iterator())
[array([1, 2, 3])]
ちなみに batch() メソッドを適用した Dataset オブジェクトは、要素がミニバッチの単位で処理される点に注意が必要となる。
たとえば、prefetch() メソッドを呼んだときはバッファが 1 つ消費される毎にミニバッチが 1 回読み込まれることになる。
Dataset#padded_batch()
Dataset オブジェクトが要素毎に shape が異なる Tensor を返す場合には、padded_batch() を使うと揃えることができる。
例えば、以下のような感じで各要素の次元が異なる場合を考える。
自然言語処理とかで文の長さが違うとかかな。
>>> mixed_shape_ds = ds.map(lambda x: tf.fill([x], x))
>>> list(mixed_shape_ds.as_numpy_iterator())
[array([1]), array([2, 2]), array([3, 3, 3]), array([4, 4, 4, 4]), array([5, 5, 5, 5, 5])]
例えば 2 つずつ要素を取り出す場合で試してみる。
>>> padded_ds = mixed_shape_ds.padded_batch(2)
取り出される要素を確認すると、各バッチ毎に次元数が揃っていることがわかる。
>>> from pprint import pprint
>>> pprint(list(padded_ds.as_numpy_iterator()))
[array([[1, 0],
[2, 2]]),
array([[3, 3, 3, 0],
[4, 4, 4, 4]]),
array([[5, 5, 5, 5, 5]])]
padded_shapes オプションを使えば、明示的にパディングするサイズを指定することもできる。
>>> padded_ds = mixed_shape_ds.padded_batch(2, padded_shapes=(10))
>>> pprint(list(padded_ds.as_numpy_iterator()))
[array([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[2, 2, 0, 0, 0, 0, 0, 0, 0, 0]]),
array([[3, 3, 3, 0, 0, 0, 0, 0, 0, 0],
[4, 4, 4, 4, 0, 0, 0, 0, 0, 0]]),
array([[5, 5, 5, 5, 5, 0, 0, 0, 0, 0]])]
パディングに使う値は padding_values オプションで指定できる。
>>> padded_ds = mixed_shape_ds.padded_batch(2, padded_shapes=(10), padding_values=tf.constant(-1, dtype=tf.int64))
>>> pprint(list(padded_ds.as_numpy_iterator()))
[array([[ 1, -1, -1, -1, -1, -1, -1, -1, -1, -1],
[ 2, 2, -1, -1, -1, -1, -1, -1, -1, -1]]),
array([[ 3, 3, 3, -1, -1, -1, -1, -1, -1, -1],
[ 4, 4, 4, 4, -1, -1, -1, -1, -1, -1]]),
array([[ 5, 5, 5, 5, 5, -1, -1, -1, -1, -1]])]
バッチサイズに満たない要素を切り捨てる場合に drop_remainder オプションを使うのは batch() メソッドと同様。
>>> padded_ds = mixed_shape_ds.padded_batch(2, padded_shapes=(10), padding_values=tf.constant(-1, dtype=tf.int64), drop_remainder=True)
>>> pprint(list(padded_ds.as_numpy_iterator()))
[array([[ 1, -1, -1, -1, -1, -1, -1, -1, -1, -1],
[ 2, 2, -1, -1, -1, -1, -1, -1, -1, -1]]),
array([[ 3, 3, 3, -1, -1, -1, -1, -1, -1, -1],
[ 4, 4, 4, 4, -1, -1, -1, -1, -1, -1]])]
Dataset#unbatch()
batch() メソッドとは反対に、各要素単位で読み込めるように戻すのが unbatch() メソッドになる。
パフォーマンス向上などを目的として、パイプラインの中にバッチ単位で処理する箇所があると、意外と使うことになる。
>>> batched_ds = ds.batch(3)
>>> unbatched_ds = batched_ds.unbatch()
>>> list(unbatched_ds.as_numpy_iterator())
[1, 2, 3, 4, 5]
ちなみに入れ子になった構造を flatten するときにも使えたりする。
>>> nested_ds = tf.data.Dataset.from_tensor_slices([[1, 2], [3, 4], [5, 6]])
>>> list(nested_ds.unbatch().as_numpy_iterator())
[1, 2, 3, 4, 5, 6]
複数のデータセットをまとめる
パイプラインによっては、複数のデータセットをひとまとめにして扱いたいことがある。
Dataset#concatenate()
複数の Dataset オブジェクトを直列につなげたいときは concatenate() メソッドを使う。
>>> ds1 = tf.data.Dataset.range(0, 5)
>>> ds2 = tf.data.Dataset.range(5, 10)
>>> concat_ds = ds1.concatenate(ds2)
>>> list(concat_ds.as_numpy_iterator())
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Dataset.zip()
concatenate() とは反対に、並列にまとめたいときは zip() が使える。
>>> ds1 = tf.data.Dataset.range(0, 5)
>>> ds2 = tf.data.Dataset.range(5, 10)
>>> zip_ds = tf.data.Dataset.zip((ds1, ds2))
>>> list(zip_ds.as_numpy_iterator())
[(0, 5), (1, 6), (2, 7), (3, 8), (4, 9)]
3 つ以上をまとめることもできる。
また、要素数に違いがあるときは短いものに合わせられる。
>>> ds3 = tf.data.Dataset.range(10, 19)
>>> zip_ds = tf.data.Dataset.zip((ds1, ds2, ds3))
>>> list(zip_ds.as_numpy_iterator())
[(0, 5, 10), (1, 6, 11), (2, 7, 12), (3, 8, 13), (4, 9, 14)]
まとめる Dataset オブジェクトは shape が異なっていても問題ない。
>>> zip_ds = tf.data.Dataset.zip((ds1, ds2, ds3.batch(2)))
>>> list(zip_ds.as_numpy_iterator())
[(0, 5, array([10, 11])), (1, 6, array([12, 13])), (2, 7, array([14, 15])), (3, 8, array([16, 17])), (4, 9, array([18]))]
その他の処理
その他の分類が難しい処理たち。
Dataset#repeat()
repeat() メソッドを使うと、Dataset オブジェクトが返す内容を繰り返すようにできる。
例えば、2 回繰り返すようにしてみる。
>>> repeat2_ds = ds.repeat(2)
>>> list(repeat2_ds.as_numpy_iterator())
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
繰り返しの回数を明示的に指定しない場合には無限ループになる。
>>> inf_loop_ds = ds.repeat()
>>> [next(it).numpy() for _ in range(20)]
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
長さやカーディナリティは取れなくなる。
>>> len(inf_loop_ds)
Traceback (most recent call last):
...
TypeError: dataset length is infinite.
>>> inf_loop_ds.cardinality().numpy()
-1
Dataset#apply()
Dataset オブジェクトを加工するための一連の処理を、一度に適用するのに Dataset#apply() メソッドが使える。
例えば、偶数の要素だけを残して値を 2 倍にする処理を考える。
そのためには、次のように Dataset オブジェクトを受け取って、処理を適用した Dataset オブジェクトを返す関数を定義する。
>>> def pipeline(ds: tf.data.Dataset) -> tf.data.Dataset:
... odd_ds = ds.filter(lambda x: x % 2 != 0)
... double_ds = odd_ds.map(lambda x: x * 2)
... return double_ds
...
あとは、関数を引数にして apply() メソッドを呼ぶだけ。
>>> applied_ds = ds.apply(pipeline)
>>> list(applied_ds.as_numpy_iterator())
[2, 6, 10]
ただ、これってメソッドチェーンの形で処理が書けるだけなので、どこに嬉しさがあるのかはあんまりよくわからない。
>>> list(pipeline(ds).as_numpy_iterator())
[2, 6, 10]
Dataset#take()
take() メソッドを使うと、先頭の要素だけを返す Dataset オブジェクトを作れる。
>>> head_ds = ds.take(2)
>>> list(head_ds.as_numpy_iterator())
[1, 2]
Dataset#skip()
take() メソッドとは反対に skip() メソッドを使うと、先頭の要素を読み飛ばす Dataset オブジェクトが作れる。
>>> tail_ds = ds.skip(2)
>>> list(tail_ds.as_numpy_iterator())
[3, 4, 5]
参考
www.tensorflow.org
www.tensorflow.org
www.tensorflow.org






")